


You might not have heard of MiniMax, but you've probably heard of Talkie, the AI chatbot taking the world by storm. In the summer of 2024, Talkie ranked fifth among the most-downloaded free entertainment apps in the US, bringing its creator, MiniMax, into the global spotlight. As the maker of this market-stunning product, the AI unicorn maintains a low profile, but its history of smart decision-making dates back a long way.
Before MoE (Mixture of Experts) became an industry consensus, MiniMax has been investing most of its efforts in it. In April 2024, MiniMax launched its first commercially deployed MoE-based LLM, MiniMax-abab 6.5, which contains over a trillion parameters and delivers performances comparable to GPT-4, Claude-3, and Gemini-1.5.
As their LLM is getting more complex and called upon more frequently, it generates an exploding amount of logs from model training and inference. These logs provide the basis for performance monitoring, optimization, and troubleshooting. The existing Grafana Loki-based logging system of MiniMax faced performance and stability issues, so they planned for an upgrade. After looking at the common industry solutions, they came to Apache Doris.
Now, all of MiniMax's business lines have been integrated with the Apache Doris-based logging system, which serves a PB-scale data size with over 99.9% availability. The query latency on billions of logs is within seconds.
The old Grafana Loki-based logging system
The design of Loki, an open-source log aggregation system, was inspired by Prometheus and developed by the Grafana Labs team. It does not have an indexing structure, but instead builds indexes only on log labels and metadata.
The major components of a Loki-based system typically include:
-
Loki: the main server responsible for log storage and querying.
-
Promtail: the agent layer for collecting logs and sending them to Loki.
-
Grafana: for user interface visualization.
To deploy Grafana Loki, each cluster should be deployed with a complete set of log collectors and Loki log storage/query services.
Loki uses an Index + Chunk design for log storage, where during ingestion, the different log streams are dispersed across various Ingesters based on a hash of the log labels, and the Ingesters are responsible for writing the log data to object storage. During querying, the Querier retrieves the relevant Chunks from the object storage based on the Index, and then performs the log matching.
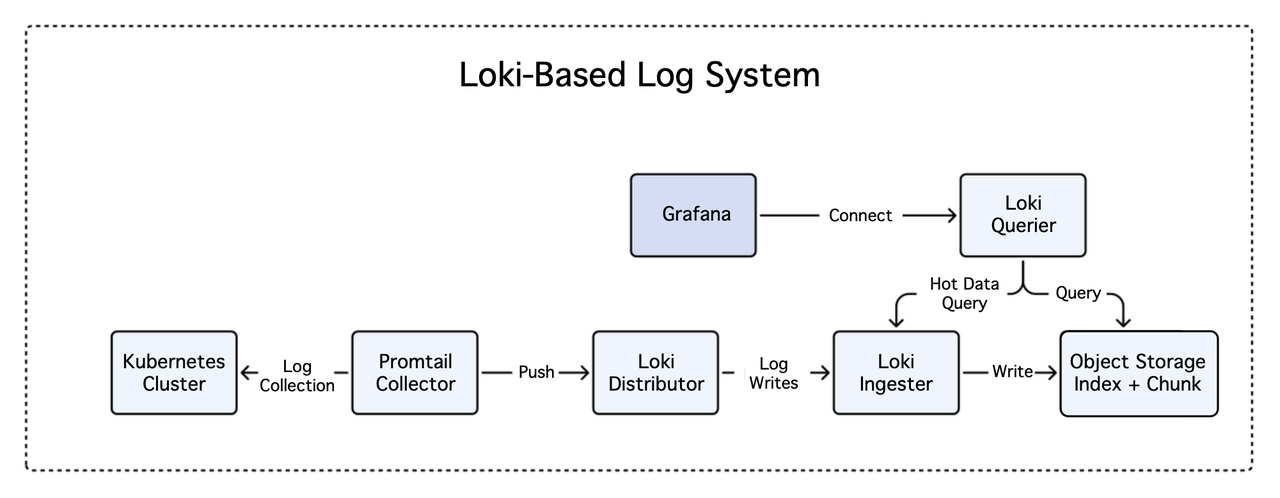
Although Grafana Loki is positioned as a lightweight, horizontally scalable, and highly available log management system, it still faces some challenges in practical business use:
-
Excessive query resource consumption: Loki does not create indexes based on the log, but instead, it only performs preliminary filtering of logs at the label granularity. Thus, for searches on the logs, it applies the query mechanism to perform full-text regular expression matching on the entire log data set. This operation can lead to spikes in resource consumption, including CPU, memory, and network bandwidth. As the volume of data being queried and the query per second (QPS) increases, Loki shows increasingly intolerable resource consumption and instability.
-
Complex architecture: In addition to the modules shown in the above diagram, Loki also includes components like the Index Gateway, Memcache, and Compactor. The large number of architectural components makes the system challenging to operate and manage, and complex to configure.
-
High maintenance cost and difficulty: MiniMax has a large number of deployed clusters, and each cluster has differences in its system, resources, storage, and network environments. The need to deploy an independent Loki architecture in each cluster adds to the maintenance difficulty.
Why Apache Doris
As one of the most data-intensive industries, AI use cases are characterized by long processing pipelines, abundant contextual data, and large per-request data volumes. Thus, the log size that MiniMax generates far exceeds those of non-AI software products of the same user base. The gigantic log size of MiniMax requires their logging system to be:
-
High-performance: They need the system to return query results on 1 billion log entries within seconds.
-
Flexible: The system should support log alerting and log metric queries, such as generating statistical trend lines for key terms.
-
Low-cost: The petabyte-scale raw log data continues to grow, so it's a make-or-break factor to keep the storage and computational costs within reasonable bounds.
After an evaluation of mature logging system architectures in the industry, MiniMax identified the following key components typically found in leading log management solutions:
-
Collection agent: collecting logs from service standard outputs and pushing the data into a central message queue.
-
Message queue: decoupling upstream and downstream components, absorbing spikes, and ensuring system stability even when downstream components are unavailable.
-
Storage and query middleware: storing and querying the log data. In a logging system, this middleware should be capable of inverted indexing to support efficient log searches.
MiniMax decided to use iLogtail for the collection agents, Kafka for the message queue, and Apache Doris as the storage and query middleware. In selecting the storage middleware, MiniMax compared the representative technologies of Apache Doris and Elasticsearch.
Based on such reference architecture, MiniMax decided to use iLogtail as the collection agent, Apache Kafka for the message queue, and Apache Doris as the storage and query middleware. The middleware decision was made after comparing Apache Doris and Elasticsearch.
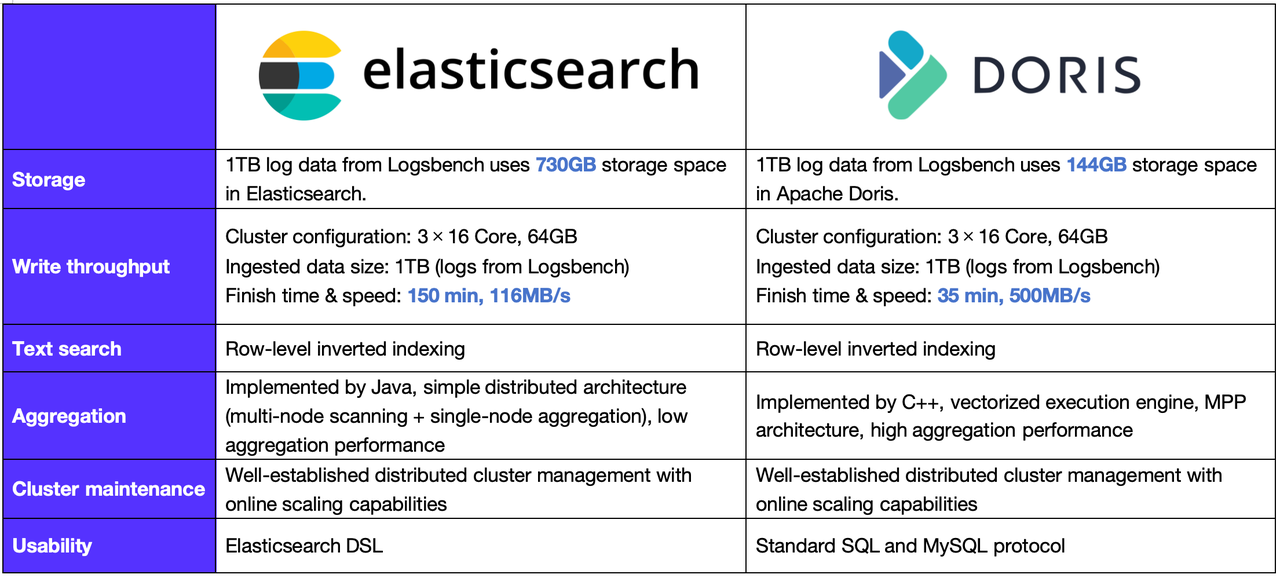
Apache Doris shows competitiveness in cost and performance. It stands out particularly in storage efficiency, write throughput, and aggregation. Additionally, its compatibility with the MySQL syntax makes it more user-friendly.
Apache Doris-based logging system
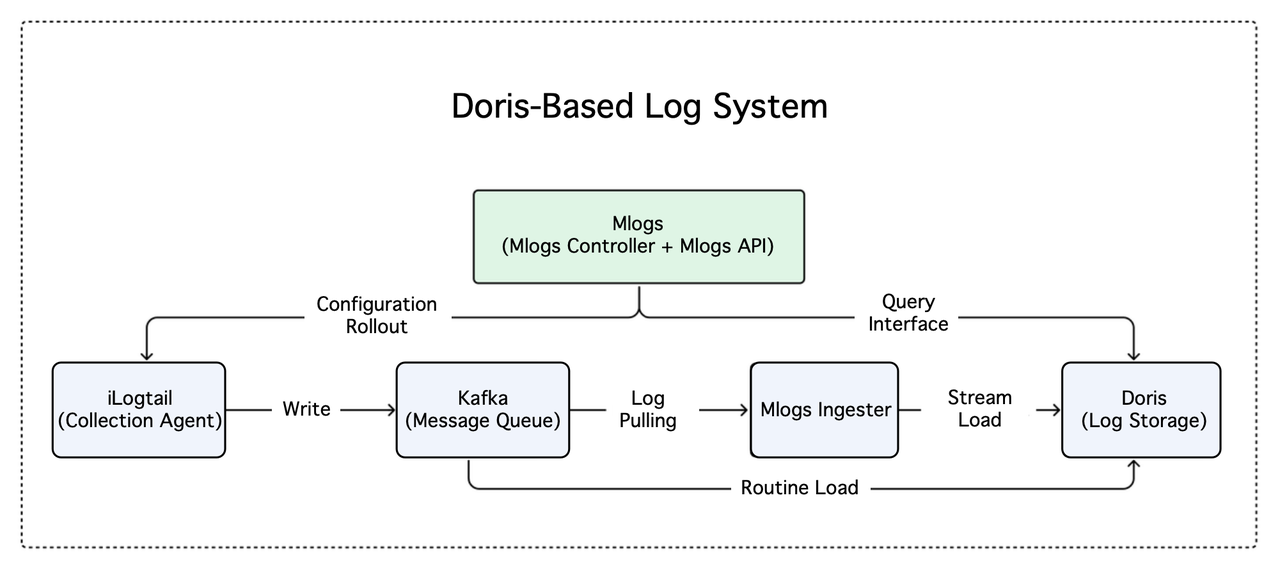
The new logging system of MiniMax, called Mlogs, is more streamlined, with a single architecture serving all clusters. The upper layer acts as the control plane for the logging system, which consists of the encapsulation of log query interfaces and the module for automatic configuration generation and distribution. The lower layer represents the data plane of the logging system, containing the log collection agent, message queue, log writer, and the Apache Doris database.
Logs generated by the cluster services are collected by iLogtail and pushed to Kafka. Part of these logs is pulled from Kafka by the Mlogs Ingester and written to the Doris cluster via the Stream Load method of Apache Doris. The rest is directly subscribed to in real-time by Doris via Routine Load, pulling the message stream from Kafka. Ultimately, Apache Doris handles the storage and querying of all log data, eliminating the need for separate deployments for each cluster.
Hands-on experience from MiniMax
Log ingestion
The new architecture utilizes both the Routine Load and Stream Load methods of Apache Doris. Routine Load is ready to use out of the box and can directly handle JSON logs without the need for additional parsing. For more complex logs that require filtering and processing, MiniMax has introduced a log writer called Mlogs Ingester between Kafka and Doris. The Mlogs Ingester parses and processes the logs before writing them to Doris via Stream Load.
Log search
For log searches, MiniMax utilizes the inverted indexes and full-text regular expression query capabilities of Apache Doris.
-
The inverted index of Apache Doris fits into a wide range of use cases and delivers high query performance. It's mainly used in
MATCHandMATCH_PHRASEqueries. -
Full-text regular expression query (
REGEXP) provides higher precision but lower performance than token-based queries. It is suitable for smaller-scale queries where precision is critical.
Performance improvement
MiniMax implements query truncation to further accelerate queries. Log data is arranged linearly in chronological order. If a query requests data of a large range, it can consume excessive computation, storage, and network resources and potentially lead to query timeouts or even system unavailability. So they set and truncate the time range of the queries to prevent overly broad queries, and pre-calculate the data volume for all tables every 15 minutes to dynamically estimate the maximum queryable time range across different tables.
Cost control
To cut down storage costs, MiniMax utilizes the tiered storage capabilities of Apache Doris. They define data within the last 7 days as hot data and data older than 7 days as cold data. Data will be moved to object storage as soon as it turns cold. Furthermore, they archive object storage data that is over 30 days old and only restore the archived data when necessary.
Value to MiniMax
Now, the Apache Doris-based logging system has been supporting all business line log data within MiniMax, serving a PB-scale data size with over 99.9% availability. It has also brought the following values to MiniMax:
-
Simplified architecture: The new system is easier to deploy and allows a single framework to serve all clusters. This reduces maintenance and management complexity, thus saving operational manpower and costs.
-
Fast query response: The new system can respond to keyword searches and aggregation queries from 1 billion log records within 2 seconds. Most log queries can return results within seconds, too.
-
High write performance: With the current hardware setups, the system can deliver a log write throughput of 10 GB/s, while maintaining data latency within seconds.
-
Low storage costs: The data compression ratio reaches 5:1 and tiered storage further reduces storage costs by 70%.
What's next
After a successful initial experience with Apache Doris, MiniMax proceeds with the next phase of its upgrade plan, which includes the following efforts:
-
Log pre-processing: introduce log sampling and structuring to improve data usability and storage efficiency.
-
Tracing: integrate the logging system with other observability systems (monitoring, alerting, tracing, etc.) to provide comprehensive operational insights.
-
Lakehousing: expand the use of Apache Doris include big data processing and analysis within MiniMax, laying the foundation for a data lakehouse.
If you have any questions or require assistance regarding Apache Doris, join the community.


