This is an in-depth introduction to the workload isolation capabilities of Apache Doris. But first of all, why and when do you need workload isolation? If you relate to any of the following situations, read on and you will end up with a solution:
- You have different business departments or tenants sharing the same cluster and you want to prevent the interference of workloads among them.
- You have query tasks of varying priority levels and you want to give priority to your critical tasks (such as real-time data analytics and online transactions) in terms of resources and execution.
- You need workload isolation but also want high cost-effectiveness and resource utilization rates.
Apache Doris supports workload isolation based on Resource Tag and Workload Group. Resource Tag isolates the CPU and memory resources for different workloads at the level of backend nodes, while the Workload Group mechanism can further divide the resources within a backend node for higher resource utilization.
Resource isolation based on Resource Tag
Let's begin with the architecture of Apache Doris. Doris has two types of nodes: frontends (FEs) and backends (BEs). FE nodes store metadata, manage clusters, process user requests, and parse query plans, while BE nodes are responsible for computation and data storage. Thus, BE nodes are the major resource consumers.
The main idea of a Resource Tag-based isolation solution is to divide computing resources into groups by assigning tags to BE nodes in a cluster, where BE nodes of the same tag constitute a Resource Group. A Resource Group can be deemed as a unit for data storage and computation. For data ingested into Doris, the system will write data replicas into different Resource Groups according to the configurations. Queries will also be assigned to their corresponding Resource Groups for execution.
For example, if you want to separate read and write workloads in a 3-BE cluster, you can follow these steps:
- Assign Resource Tags to BE nodes: Bind 2 BEs to the "Read" tag and 1 BE to the "Write" tag.
- Assign Resource Tags to data replicas: Assuming that Table 1 has 3 replicas, bind 2 of them to the "Read" tag and 1 to the "Write" tag. Data written into Replica 3 will be synchronized to Replica 1 and Replica 2 and the data synchronization process consumes few resources of BE 1 and BE2.
- Assign workload groups to Resource Tags: Queries that include the "Read" tag in their SQLs will be automatically routed to the nodes tagged with "Read" (in this case, BE 1 and BE 2). For data writing tasks, you also need to assign them with the "Write" tag, so they can be routed to the corresponding node (BE 3). In this way, there will be no resource contention between read and write workloads except the data synchronization overheads from replica 3 to replicate 1 and 2.
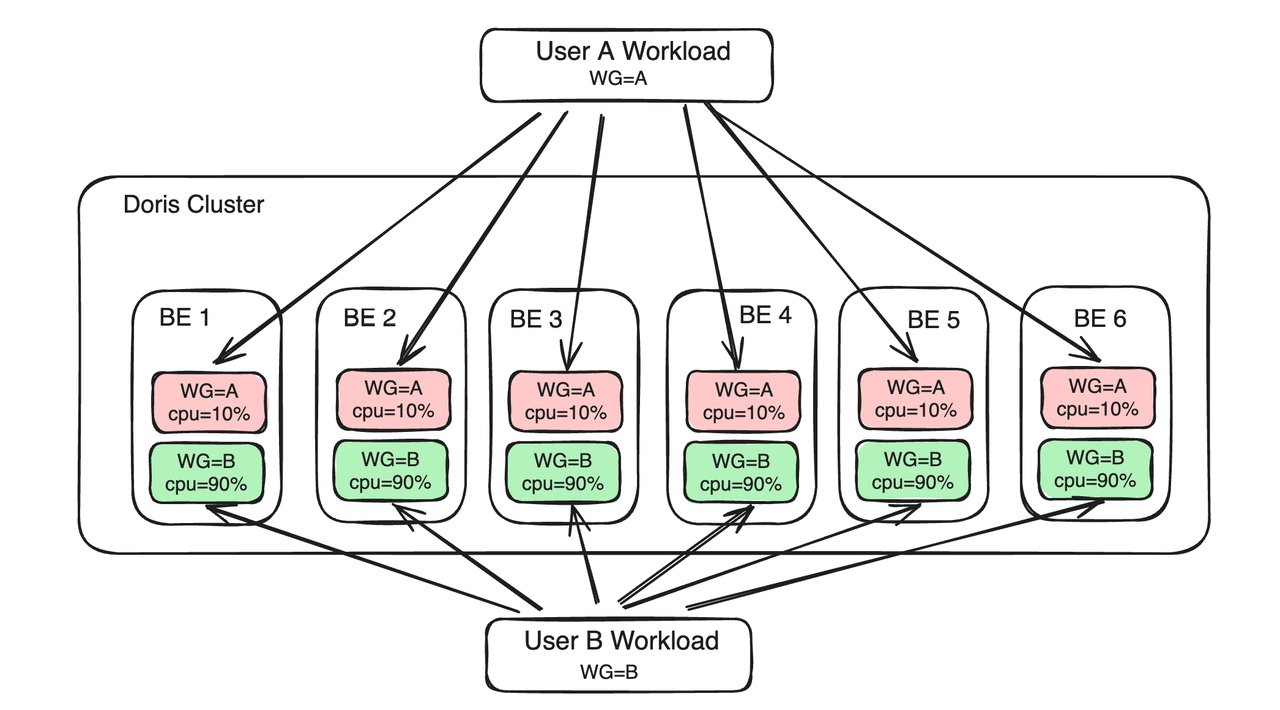
Resource Tag also enables multi-tenancy in Apache Doris. For example, computing and storage resources tagged with "User A" are for User A only, while those tagged with "User B" are exclusive to User B. This is how Doris implements multi-tenant resource isolation with Resource Tags at the BE side.
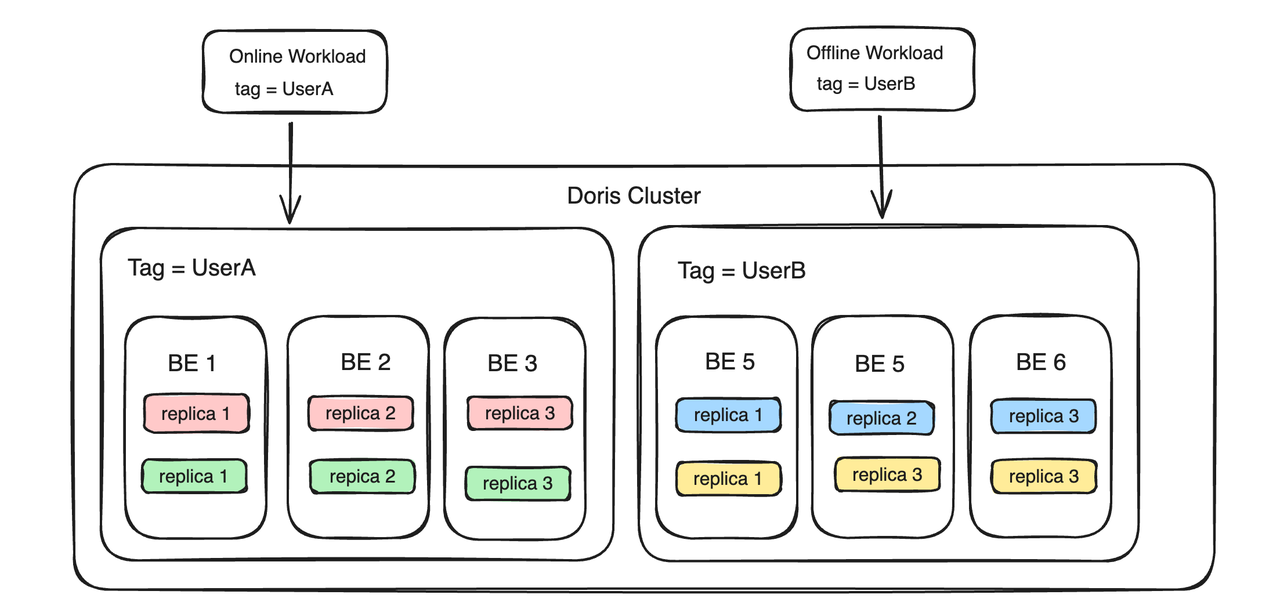
Dividing the BE nodes into groups ensures a high level of isolation:
- CPU, memory, and I/O of different tenants are physically isolated.
- One tenant will never be affected by the failures (such as process crashes) of another tenant.
But it has a few downsides:
- In read-write separation, when the data writing stops, the BE nodes tagged with "Write" become idle. This reduces overall cluster utilization.
- Under multi-tenancy, if you want to further isolate different workloads of the same tenant by assigning separate BE nodes to each of them, you will need to endure significant costs and low resource utilization.
- The number of tenants is tied to the number of data replicas. So if you have 5 tenants, you will need 5 data replicas. That's huge storage redundancy.
To improve on this, we provide a workload isolation solution based on Workload Group in Apache Doris 2.0.0, and enhanced it in Apache Doris 2.1.0.
Workload isolation based on Workload Group
The Workload Group-based solution realizes a more granular division of resources. It further divides CPU and memory resources within processes on BE nodes, meaning that the queries in one BE node can be isolated from each other to some extent. This avoids resource competition within BE processes and optimizes resource utilization.
Users can relate queries to Workload Groups, and thus limit the percentage of CPU and memory resources that a query can use. Under high cluster loads, Doris can automatically kill the most resource-consuming queries in a Workload Group. Under low cluster loads, Doris can allow multiple Workload Groups to share idle resources.
Doris supports both CPU soft limit and CPU hard limit. The soft limit allows Workload Groups to break the limit and utilize idle resources, enabling more efficient utilization. The hard limit is a hard guarantee of stable performance because it prevents the mutual impact of Workload Groups.
(CPU soft limit and CPU hard limit are contradictory to each other. You can choose between them based on your own use case.)
Its differences from the Resource Tag-based solution include:
- Workload Groups are formed within processes. Multiple Workload Groups compete for resources within the same BE node.
- The consideration of data replica distribution is out of the picture because Workload Group is only a way of resource management.
CPU soft limit
CPU soft limit is implemented by the cpu_share parameter, which is similar to weights conceptually. Workload Groups with higher cpu_share will be allocated more CPU time during a time slot.
For example, if Group A is configured with a cpu_share of 1, and Group B, 9. In a time slot of 10 seconds, when both Group A and Group B are fully loaded, Group A and Group B will be able to consume 1s and 9s of CPU time, respectively.
What happens in real-world cases is that, not all workloads in the cluster run at full capacity. Under the soft limit, if Group B has low or zero workload, then Group A will be able to use all 10s of CPU time, thus increasing the overall CPU utilization in the cluster.
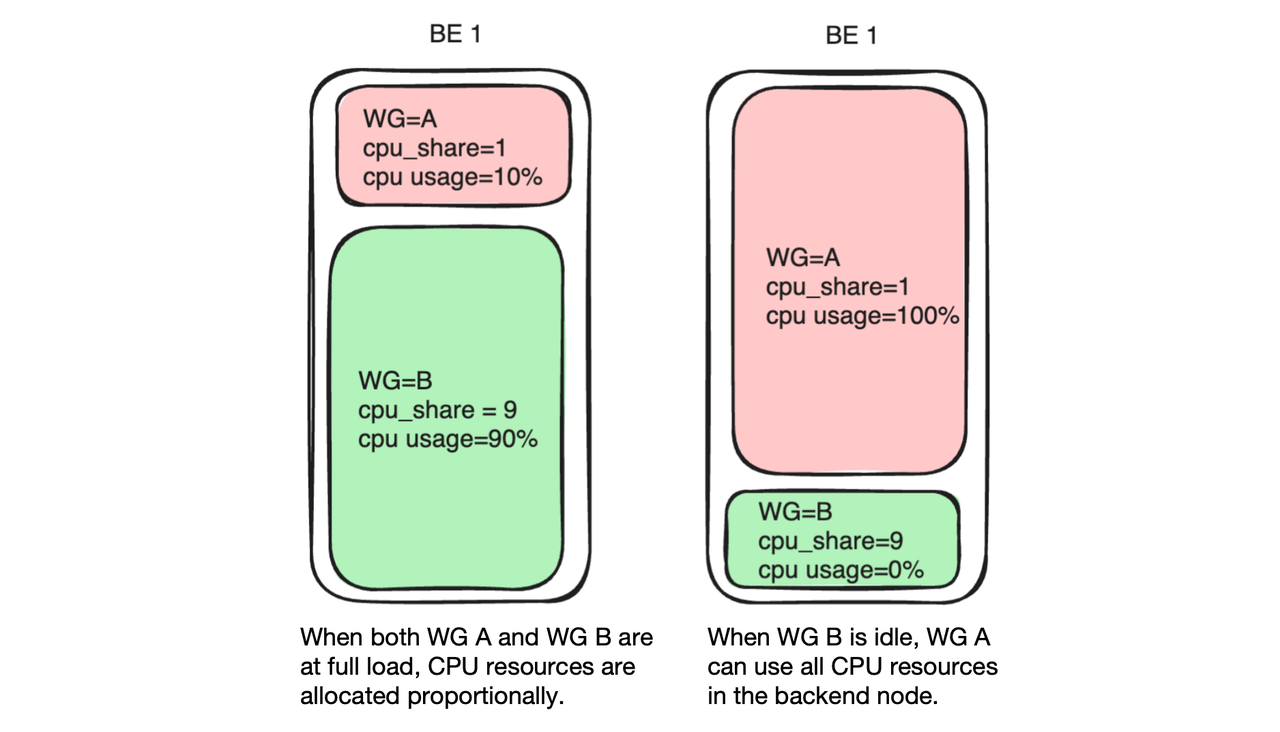
A soft limit brings flexibility and a higher resource utilization rate. On the flip side, it might cause performance fluctuations.
CPU hard limit
CPU hard limit in Apache Doris 2.1.0 is designed for users who require stable performance. In simple terms, the CPU hard limit defines that a Workload Group cannot use more CPU resources than its limit whether there are idle CPU resources or not.
This is how it works:
Suppose that Group A is set with cpu_hard_limit=10% and Group B with cpu_hard_limit=90%. If both Group A and Group B run at full load, Group A and Group B will respectively use 10% and 90% of the overall CPU time. The difference lies in when the workload of Group B decreases. In such cases, regardless of how high the query load of Group A is, it should not use more than the 10% CPU resources allocated to it.
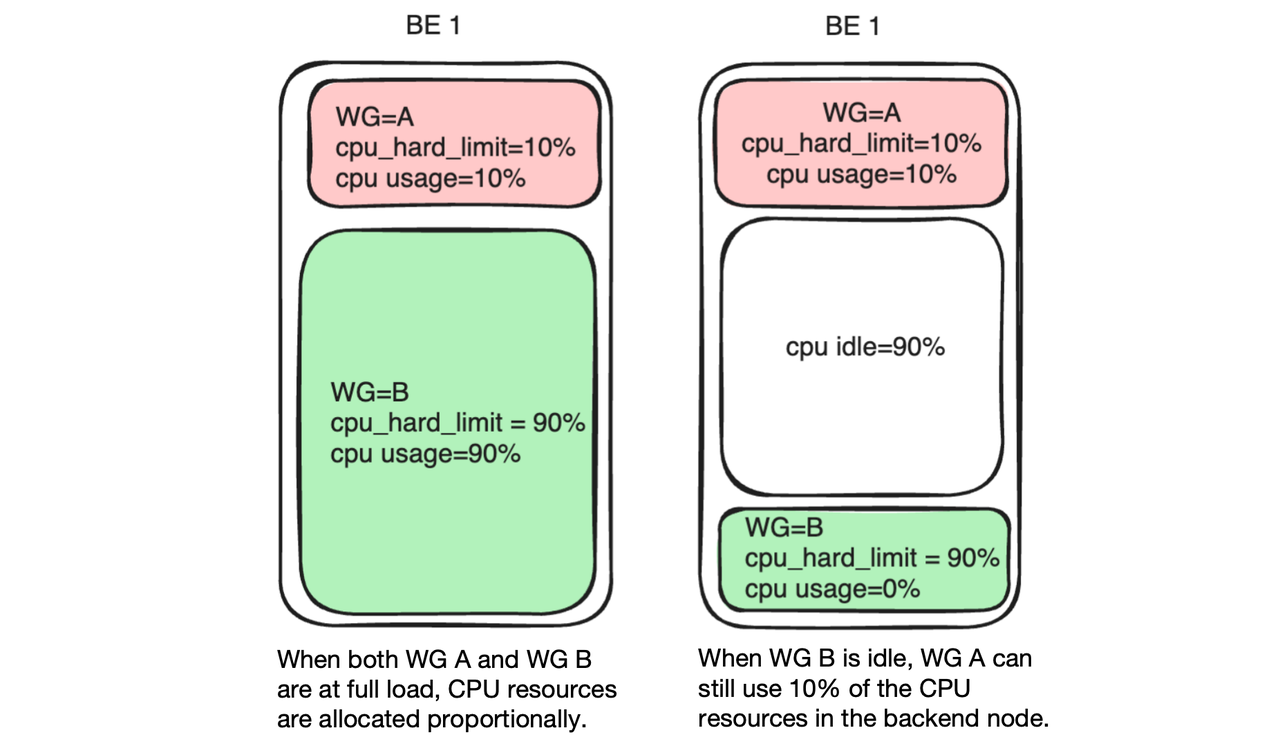
As opposed to soft limit, a hard limit guarantees stable system performance at the cost of flexibility and the possibility of a higher resource utilization rate.
Memory resource limit
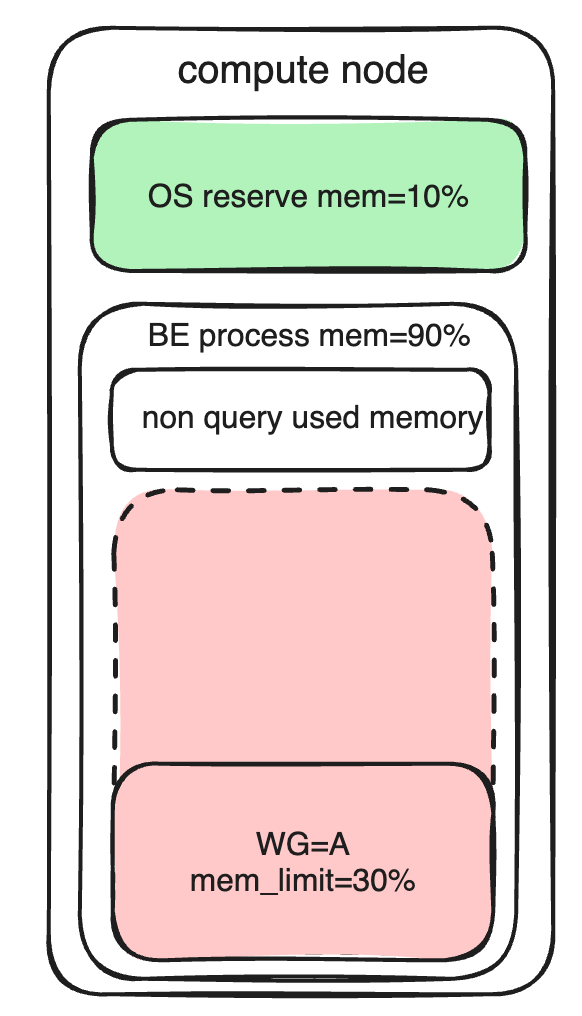
The memory of a BE node comprises the following parts:
- Reserved memory for the operating system.
- Memory consumed by non-queries, which is not considered in the Workload Group's memory statistics.
- Memory consumed by queries, including data writing. This can be tracked and controlled by Workload Group.
The memory_limit parameter defines the maximum (%) memory available to a Workload Group within the BE process. It also affects the priority of Resource Groups.
Under initial status, a high-priority Resource Group will be allocated more memory. By setting enable_memory_overcommit, you can allow Resource Groups to occupy more memory than the limits when there is idle space. When memory is tight, Doris will cancel tasks to reclaim the memory resources that they commit. In this case, the system will retain memory resources for high-priority resource groups as much as possible.
Query queue
It happens that the cluster is undertaking more loads than it can handle. In this case, submitting new query requests will not only be fruitless but also interruptive to the queries in progress.
To improve on this, Apache Doris provides the query queue mechanism. Users can put a limit on the number of queries that can run concurrently in the cluster. A query will be rejected when the query queue is full or after a waiting timeout, thus ensuring system stability under high loads.
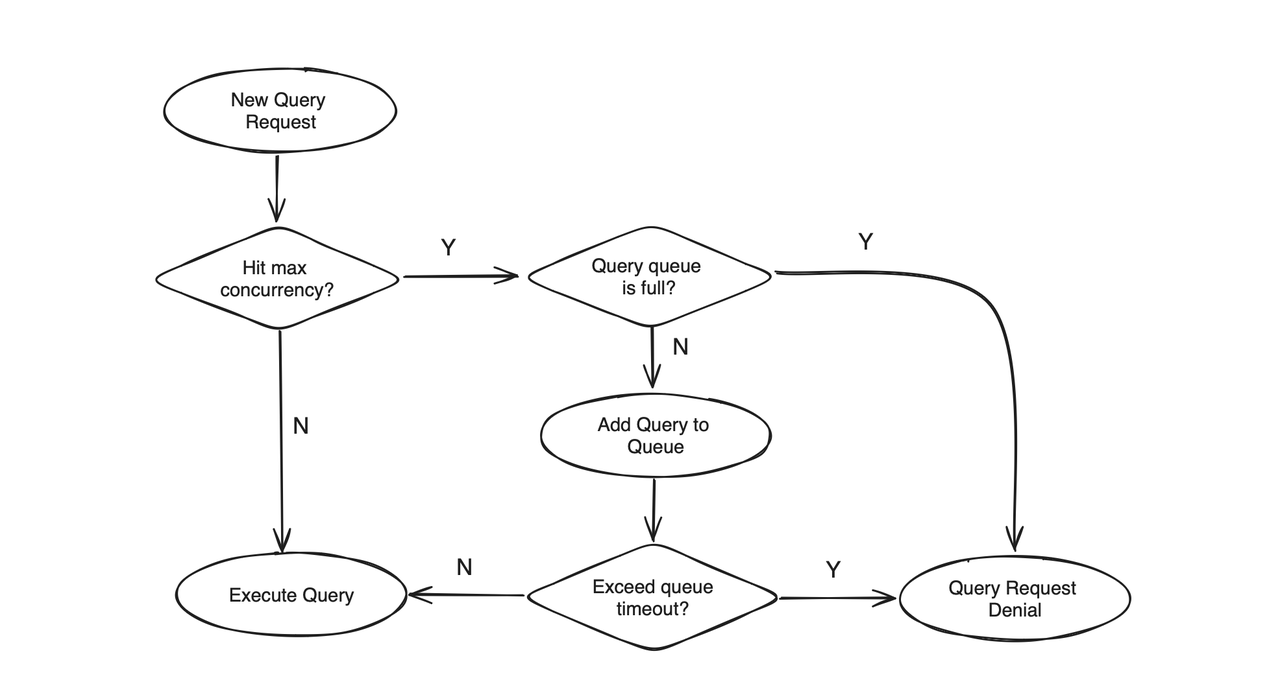
The query queue mechanism involves three parameters: max_concurrency, max_queue_size, and queue_timeout.
Tests
To demonstrate the effectiveness of the CPU soft limit and hard limit, we did a few tests.
- Environment: single machine, 16 cores, 64GB
- Deployment: 1 FE + 1 BE
- Dataset: ClickBench, TPC-H
- Load testing tool: Apache JMeter
CPU soft limit test
Start two clients and continuously submit queries (ClickBench Q23) with and without using Workload Groups, respectively. Note that Page Cache should be disabled to prevent it from affecting the test results.
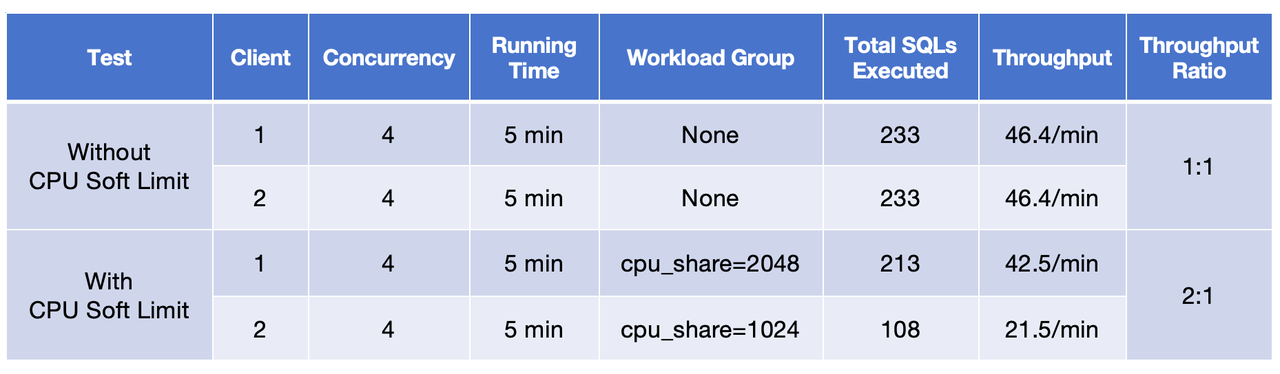
Comparing the throughputs of the two clients in both tests, it can be concluded that:
- Without configuring Workload Groups, the two clients consume the CPU resources on an equal basis.
- Configuring Workload Groups and setting the
cpu_shareto 2:1, the throughput ratio of the two clients is 2:1. With a highercpu_share, Client 1 is provided with a higher portion of CPU resources, and it delivers a higher throughput.
CPU hard limit test
Start a client, set cpu_hard_limit=50% for the Workload Group, and execute ClickBench Q23 for 5 minutes under a concurrency level of 1, 2, and 4, respectively.
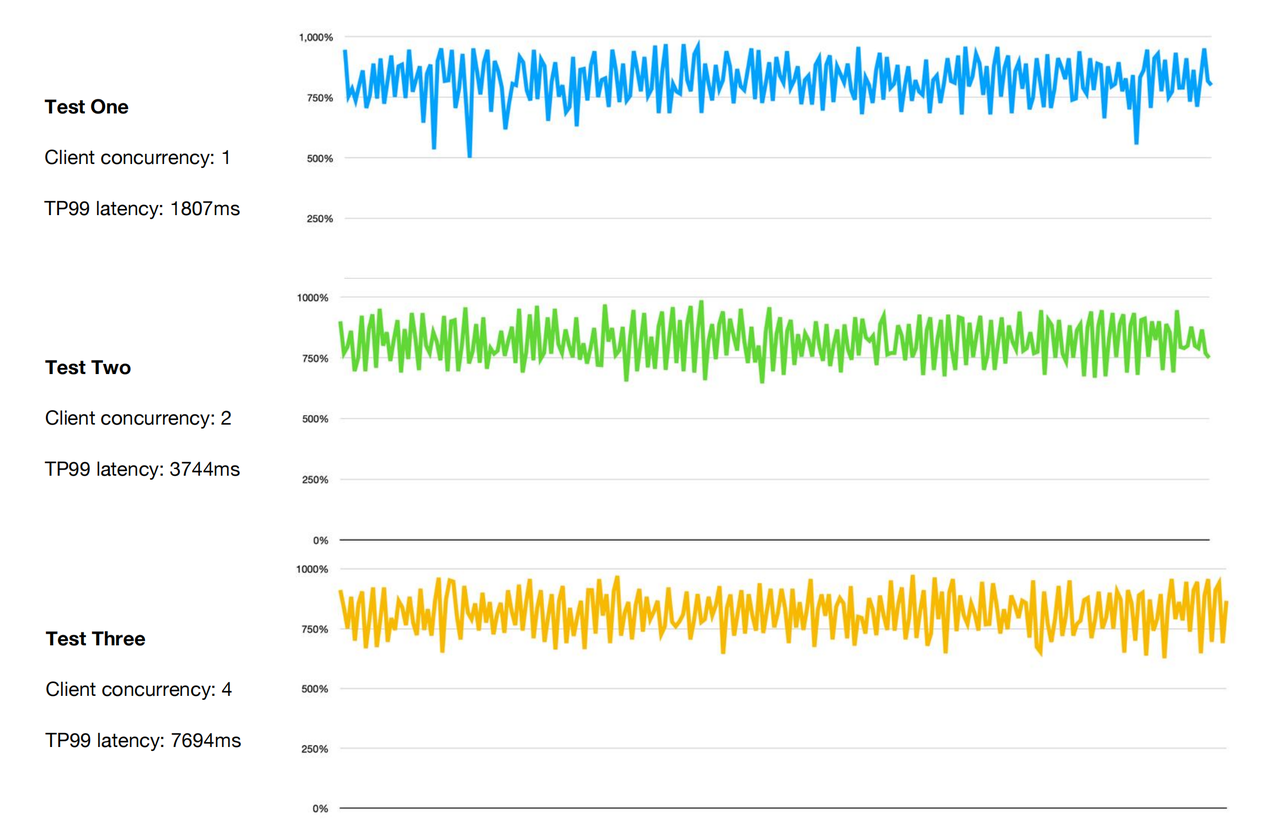
As the query concurrency increases, the CPU utilization rate remains at around 800%, meaning that 8 cores are used. On a 16-core machine, that's 50% utilization, which is as expected. In addition, since CPU hard limits are imposed, the increase in TP99 latency as concurrency rises is also an expected outcome.
Test in simulated production environment
In real-world usage, users are particularly concerned about query latency rather than just query throughput, since latency is more easily perceptible in user experience. That's why we decided to validate the effectiveness of Workload Group in a simulated production environment.
We picked out a SQL set consisting of queries that should be finished within 1s (ClickBench Q15, Q17, Q23 and TPC-H Q3, Q7, Q19), including single-table aggregations and join queries. The size of the TPC-H dataset is 100GB.
Similarly, we conduct tests with and without configuring Workload Groups.
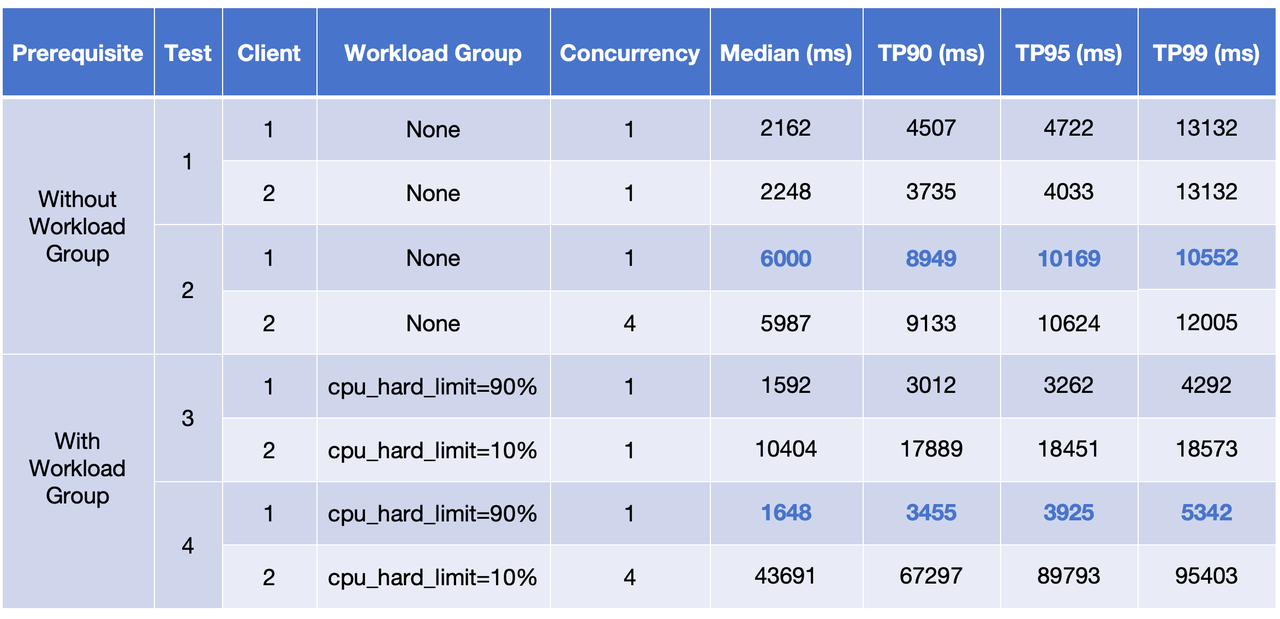
As the results show:
- Without Workload Group (comparing Test 1 & 2): When dialing up the concurrency of Client 2, both clients experience a 2~3-time increase in query latency.
- Configuring Workload Group (comparing Test 3 & 4): As the concurrency of Client 2 goes up, the performance fluctuation in Client 1 is much smaller, which is proof of how it is effectively protected by workload isolation.
Recommendations & plans
The Resource Tag-based solution is a thorough workload isolation plan. The Workload Group-based solution realizes a better balance between resource isolation and utilization, and it is complemented by the query queue mechanism for stability guarantee.
So which one to choose for your use case? Here is our recommendation:
- Resource Tag: for use cases where different business lines of departments share the same cluster, so the resources and data are physically isolated for different tenants.
- Workload Group: for use cases where one cluster undertakes various query workloads for flexible resource allocation.
In future releases, we will keep improving user experience of the Workload Group and query queue features:
- Freeing up memory space by canceling queries is a brutal method. We plan to implement that by disk spilling, which will bring higher stability in query performance.
- Since memory consumed by non-queries in the BE is not included in Workload Group's memory statistics, users might observe a disparity between the BE process memory usage and Workload Group memory usage. We will address this issue to avoid confusion.
- In the query queue mechanism, cluster load is controlled by setting the maximum query concurrency. We plan to enable dynamic maximum query concurrency based on resource availability at the BE. This is to create backpressure on the client side and thus improve the availability of Doris when clients keep submitting high loads.
- The main idea of Resource Tag is to group the BE nodes, while that of Workload Group is to further divide the resources of a single BE node. For users to grasp these ideas, they need to learn about the concept of BE nodes in Doris first. However, from an operational perspective, users only need to understand the resource consumption percentage of each of their workloads and what priority they should have when cluster load is saturated. Thus, we will try and figure out a way to flatten the learning curve for users, such as keeping the concept of BE nodes in the black box.
For further assistance on workload isolation in Apache Doris, join the Apache Doris community.