- Products
- Solutions
- Docs
- Resources
- Contact us
Start Free
Modern All-in-One Data Platform
- Various data integration methods
- High efficiency & low cost
- One data warehouse for multiple analytic needs
Challenges
Companies build their own big data analytic platform to collect internal data as the statistical basis for sales, marketing, customer services, operation, and finance to improve their decision-making.
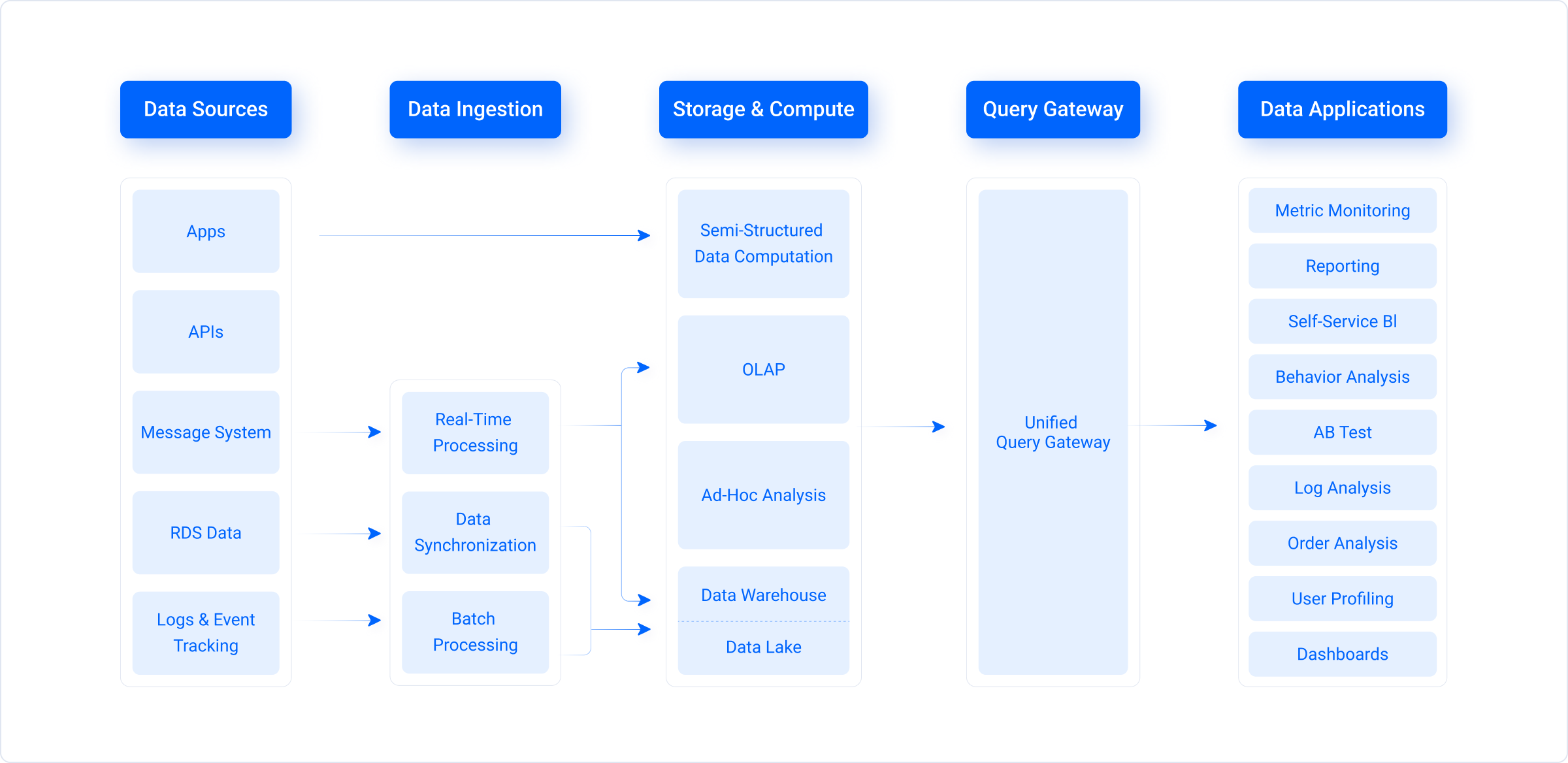
The above shows the typical architecture for big data platforms. Common solutions are often challenged by the following problems.
High complexity
Corporate data platforms often consist of multiple data warehouses and data lakes for batch processing and ad-hoc analysis, in addition to a variety of upstream and downstream components. Thus, they require a big team of maintainers who must have a good command of all tools and tech stacks.High cost
Within a data platform, parallel processing systems can cause redundant data storage in multiple components. Moreover, as data varies in access frequency, the strong coupling of hot and cold data is a big waste of storage resources.High latency
For companies, system scalability is often prioritized over single-node performance. However, long and complicated data pipelines result in high latency in data processing, which is the opposite of what online reporting and data analytics need.High exclusivity
The complexity of component integration makes it hard to introduce new functionality to the existing data platform. This undermines a company's adaptability to changes and new business needs. Meanwhile, the gap between cloud and on-premise deployments is another barrier to system openness.
The VeloDB solution
A data warehouse for high-performance reporting, ad-hoc analytics, and incremental ELT.
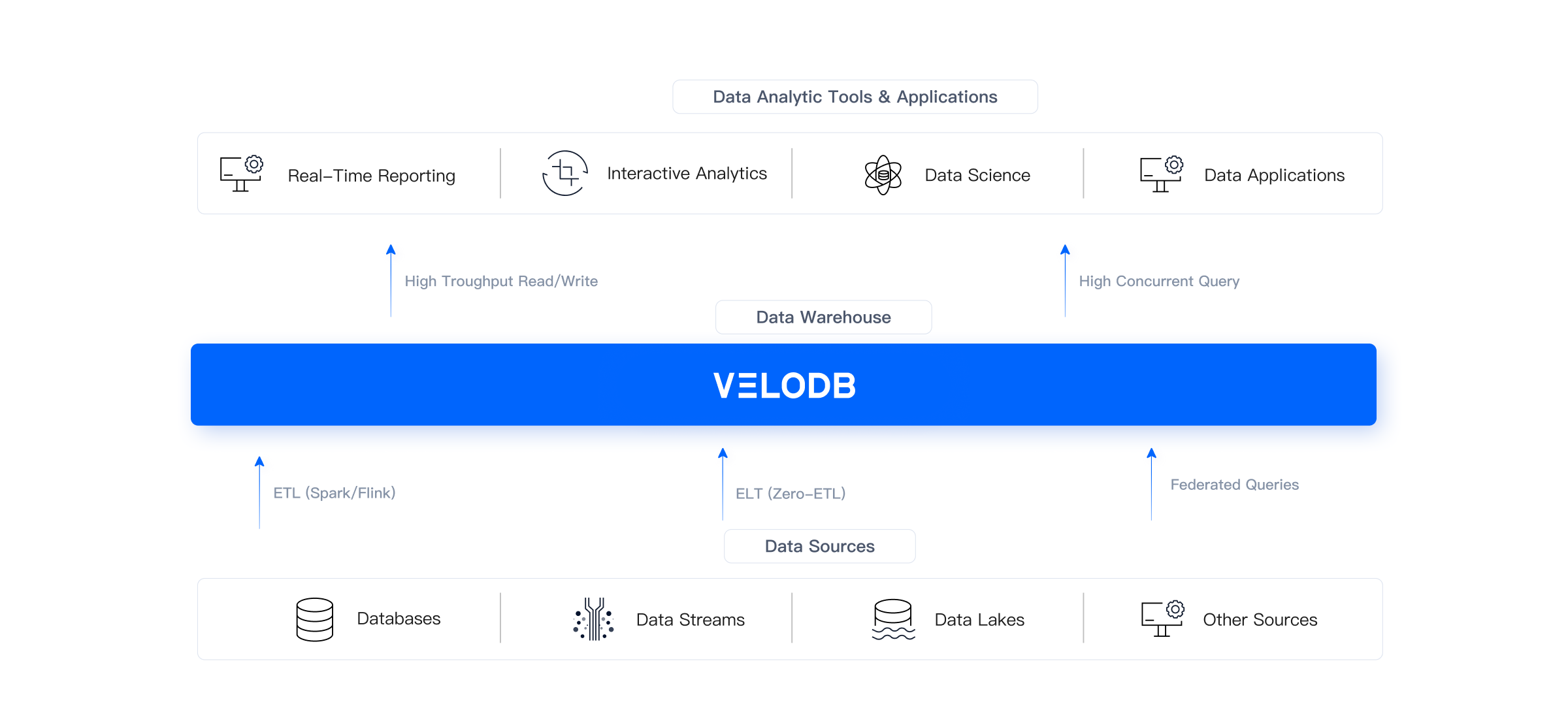
 Data integration
Data integration- ·In addition to ETL based on Spark and Flink, VeloDB supports lightweight ELT, which means the data transforming workload can be moved from Spark and Flink to the data warehouse.
- ·VeloDB provides federated query capabilities. For ad-hoc queries or data lake access, VeloDB can be used as a unified query gateway without having to ingest relevant data into VeloDB.
 High efficiency & low cost
High efficiency & low cost- ·VeloDB Cloud enables storage-compute separation, tiered storage, and elastic scaling to reduce costs.
- ·VeloDB Enterprise can be deployed in various environments. It ships with its own operation and maintenance tools and provides multiple computing clusters for workload isolation.
- ·VeloDB Cloud is compatible with Apache Doris. Users can migrate data between the two and protect themselves from vendor lock-in.
 Multiple analytics needs
Multiple analytics needs- ·Adopting the MySQL protocol, VeloDB can be used in business intelligence, data engineering, and data science. It is capable of data transformation when used in combination with DBT. It also provides functionalities such as concurrent reading and incremental data import/export.
Try VeloDB now
VeloDB Cloud
Fully managed, cloud-native, real-time data warehouse service
Start freeVeloDB Enterprise
Self-managed software on premises, on VMs, or K8s
Start freeTrust Center|User Agreement|Privacy Policy
© 2025 VeloDB Inc. All rights reserved. Apache Doris and its logo are trademarks of The Apache Software Foundation