Special Thanks:
The Apache Doris community would like to extend our gratitude to Dien for sharing his valuable experience and best practices in migrating from BigQuery to Apache Doris in this insightful and informative article. Dien is also an active member of the Apache Doris open-source community, and we are truly appreciative of his ongoing support.
This article is written by Dien, Tran Thanh and originally posted on Medium.
The problem posed
To cut BigQuery costs, my previous employer who worked at a retail company (Regrettably, I'm not at liberty to disclose the name) asked me as an Advisor to research and design a data platform on-premises. In the data-driven company, it spent about $6,000 on BigQuery (The current scanning cost is $8.44 per TB — Pay-as-you-go, not including taxes and storage fees).
I summarize the sources of the high BigQuery cost into the following:
-
ETL: More than 500 tables drawn from CRM system, OMS system, tracking on web/app, affiliates, marketplace, and social media... (Only the tables necessary for the current requirements are stored. For tables that are not actively needed, the data is stored as Parquet files in Google Cloud Storage (GCS)).
-
Tables: The departments built nearly 120 tables in the data mart, including the reports of accounting, marketing, sales, operations, and BOD.
-
Dashboards: There are 45 dashboards, each having 7–10 charts on average.
-
Queries: The systems running campaigns interact with BigQuery, as they need to query through a large volume of data (coded in Java, reading data from BigQuery).
The situation was complicated. After reviewing the data usage, I realized that the existing data lakehouse has already optimized the use of BigQuery. They have applied the techniques suggested by Google, such as partitioning, clustering, materialized views, denormalization, and caching. Additionally, they have workers monitoring the audit logs to detect expensive queries and alerts to ensure the queries follow the established rules. That is to say, there was little room for further optimization on the BigQuery side.
Given this scenario, using an open-source on-premises solution appeared to be the choice. However, this would come with the trade-off of increased operational costs. Those who have migrated from a cloud-based solution to an on-premises one will understand the challenges associated with this decision.
Approach to the problem
The key requirements for this migration process are:
-
Leverage the existing ETL pipeline with minimal changes.
-
Reuse the existing data marts that have been built by various teams. As 90% of them are built using SQL, the new data lakehouse system needs to have strong SQL support to enable the reuse of the existing workflows.
-
Ensure the current services (written in Java) can seamlessly connect to the new lakehouse, with minimal changes to the application logic.
-
Rebuild the existing dashboards on Metabase (a BI tool). This could be challenging as there might be differences in syntax or support for certain functions (e.g., window functions) between BigQuery and the new system.
-
Achieve good system performance, stability, flexibility, and easy scalability.
-
Hopefully, be able to read data from Apache Iceberg, as this is where the Machine Learning team exports their model results.
-
Hopefully, store vector data for the AI chatbot.
-
Ensure the new data lakehouse is easy for the existing teams to learn and adopt, especially in terms of SQL syntax.
-
The long-term maintenance costs of the new system should be low, with a reasonable initial effort to understand the operational aspects.
Based on the information provided, I found Apache Doris, an open source data warehouse, to be a suitable solution. (A friend introduced it to me before, when performing this migration, I had 5 months of experience working with Doris.)
Around 20TB of data needs to be scanned daily. According to BigQuery charts, the peak hours are 00:00–06:00, 8:30–11:00 and 14:30–16 :00). I use the following hardware configuration:
-
3 Follower nodes, each with 20GB RAM, 12 CPU, and 200GB SSD
-
1 Observer node with 8GB RAM, 8 CPU, and 100GB SSD
-
3 Backend nodes, each with 64GB RAM, 32 CPU, and 3TB SSD
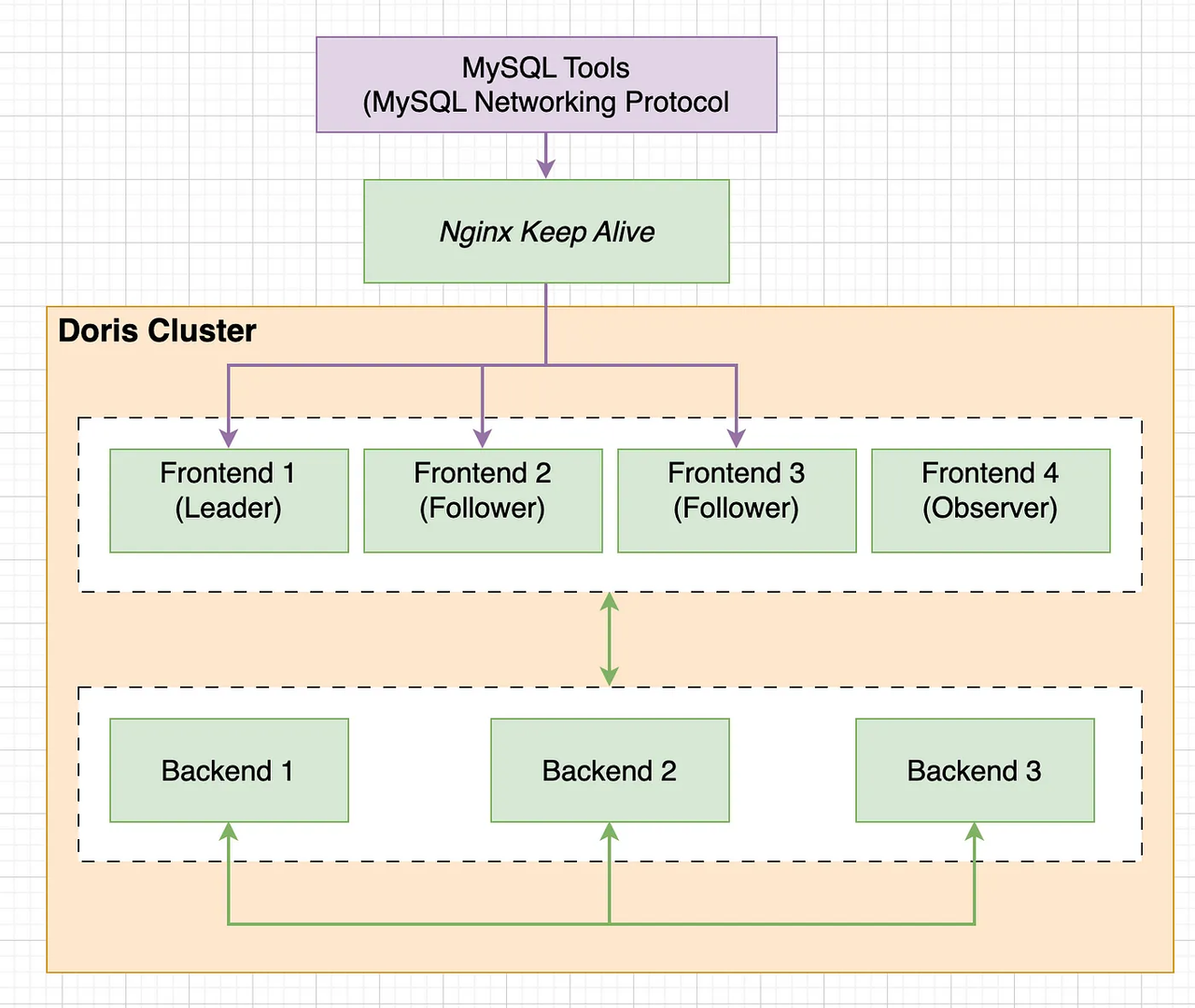
With this configuration, the estimated monthly cost is around 37 million VND (using a server service provided by a Vietnamese company and the pricing may vary across different providers.).
Reasons to choose Apache Doris:
-
Doris is being actively developed by Baidu to meet their own needs. It is widely used by other major tech companies such as Alibaba, Tencent, and Xiaomi... and recently many technology companies in India.
-
The Doris community, while smaller compared to Clickhouse, has an active Slack group where users can get support and direct answers from the developers, including those who have previously encountered and resolved similar issues.
-
Doris supports the MySQL protocol, allowing applications and tools that can connect to MySQL to also connect to Doris.
-
Doris provides high availability, where data can still be queried even if a node goes down, as long as the table's replication settings are configured properly.
-
Doris can be scaled both horizontally and vertically. In cases where local storage is insufficient, data can be stored on HDFS, S3, GCS, and accessed using federated queries.
-
Doris' performance is optimized through the Massive Parallel Processing architecture, and features like predicate pushdown, partitioning, various Indexing mechanisms, and rollup (very useful). It also uses a columnar data format and provides flexible join capabilities, including broadcast joins and local joins utilizing replicas to avoid data shuffling. It provides more flexible upsert than ClickHouse.
There are many more reasons, but I've only highlighted a part of them above.
Problem solving
Migrate ETL streams from data sources
Below is the high-level data architecture of the data flow before migration:
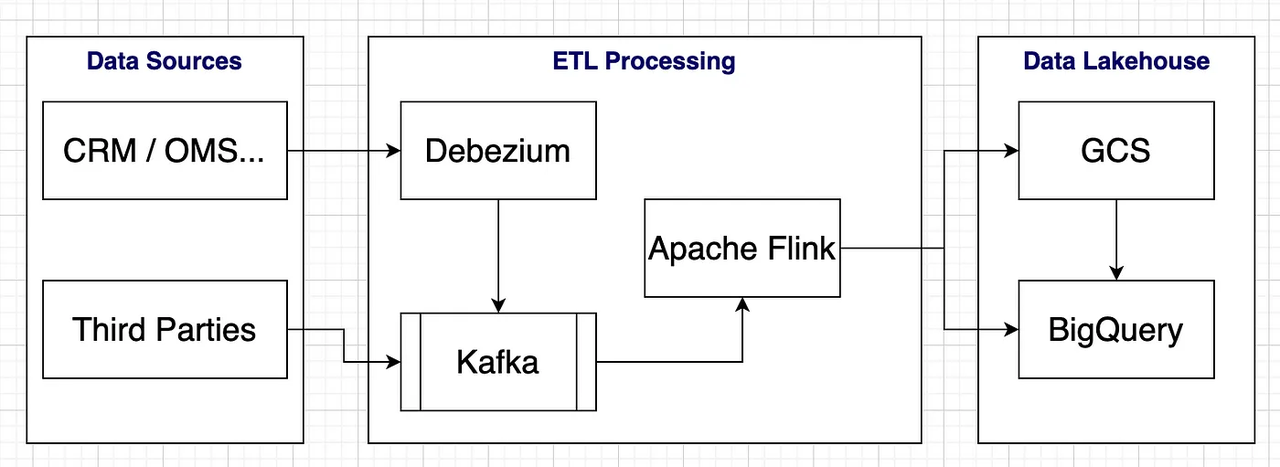
The company has saved costs by using open-source solutions for the ETL processing components, and it used only GCS and BigQuery. I will not delve into the details of the architecture here but keep the explanation simple to provide a high-level understanding of the migration process. If a more comprehensive solution is required, there are options like Apache Iceberg and Trino that can be leveraged for ad-hoc processing, A/B testing, etc.
This is the architecture after migration.
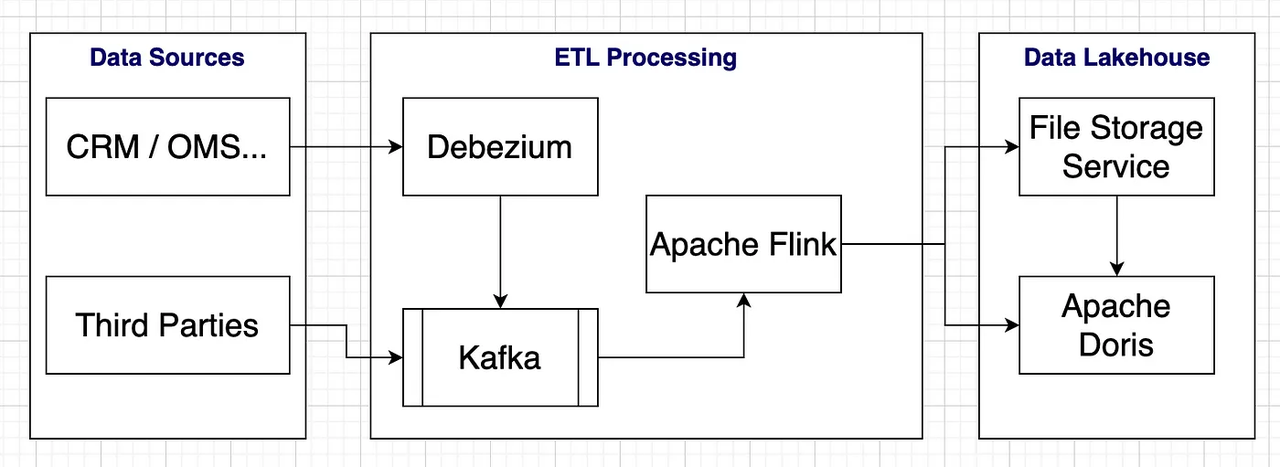
To minimize the changes, we have used a similar architecture, where Apache Doris provides a connector that allows Apache Flink to directly upsert data into it.
The File Storage Service is provided by the server company. (The client connection is similar to S3, and I guess the underlying core could be MinIO.)
Apache Doris supports reading real-time data directly from Kafka and performing simple ETL, but to reduce the burden on Doris and leverage the processing capabilities of Apache Flink, we have only created an abstraction to push the data into Doris, which is quite straightforward.
Migrating the old data is more challenging, and we have implemented the following steps:
-
Step 1: A script reads the schema for each table on BigQuery, and then creates corresponding tables with the same schema and partition columns on Doris (luckily, we don't have to deal with complex data types). Currently, Doris does not support clustering columns, but it does provide various indexes such as Bitmap Index, Prefix Index, Bloom Filter Index, and Inverted Index, depending on the use case.
-
Step 2: A script exports each table from BigQuery into Parquet files and stores them in GCS.
-
Step 3: A script directly reads the files from GCS and loads them into Doris (Doris supports reading data from File Storage System quite easily, requiring only a simple SQL statement).
During the migration, we have prepared scripts and techniques to ensure data consistency between BigQuery and Doris when the new ETL flow on Doris starts consuming the new data.
Migrate data marts flow
This part is quite straightforward as the old flow used Apache Airflow, where they defined SQL (easy to manage SQL version when building Data Marts) and then used the Google Cloud BigQuery Operator to interact with BigQuery. In this part, I have replaced the BigQuery Operator with the MySQL Operator to connect to Doris. The Doris SQL is compatible with 90% of the old flow, so I can reuse the old SQL statements.
Migrate services pointing to BigQuery
This part is also easy as the majority of the services use simple custom SQL. The tables they use are mostly pre-calculated (denormalized, big tables, or materialized views), so there is almost no need for changes, except for the connection part to Doris, but we don't have to change the code logic.
Migrate dashboards in Metabase
When Metabase connects to Doris, some dashboards will throw errors due to different function syntax. For example, Doris uses the Window Functions such as LEAD(expr, offset, default) OVER (partition_by_clause order_by_clause), while in BigQuery, it is LEAD(expr) OVER (partition_by_clause order_by_clause). Such difference can lead to logical errors, so we need to remove those charts and rebuild the new syntax on Doris.
Monitoring
After all the migration, we use Airflow to check the data of both BigQuery and Doris for each table and each chart. When a table has a discrepancy, we will zoom in to handle it. Overall, we haven't seen any complex errors, and the discrepancy rate is less than 5%.
Evaluation
After the ETL pipeline ran stably for a week, I provided the team with a trial version. After 4 weeks of testing, the performance remained stable, with occasional failures of a Frontend (FE) node. (When one FE node died, the system could still be queried though. Only backend failures would impact performance since that means the parallel server capacity could not be fully utilized. When a failure occurred, the system would self-recover within 2 seconds). During peak hours, queries were often slow because the ETL job consuming over 70% of the resources. The solution was to reconfigure the resource allocation to restrict the ETL account from consuming more than 40% of resources. (Doris provides a mechanism to share resources between account groups, where normally unused resources can be borrowed, but during contention each group is limited to its allocated portion, so limiting ETL to 40% resolved the issue during high concurrent usage.)
The team plans to run the old and new systems in parallel for another 2-3 weeks. If everything checks out, they will then shut down the BigQuery pipeline.
Currently, the new system is not fully optimized, and the team hasn't utilized all the features that Apache Doris provides. With more time to explore, it seems they could solve many more problems.
The implementation was carried out by 1 Data Engineer, 1 Software Engineer, and 1 Data Analyst over 4 weeks.
Advantages of the new system
-
The biggest advantage is the cost savings. The monthly cost has been reduced from $6,000 to $1,500.
-
It supports seamless data import from Apache Iceberg. The Machine Learning and data mining team can directly import data without needing to create a separate pipeline like with BigQuery.
-
It supports vector data storage for AI chatbots. Data can be directly imported from the File Store Service (S3) instead of having to push it to Redis as before.
-
It provides efficient data aggregation through the Rollup mechanism.
-
It allows hybrid hot and cold storage within a single table. The older, less frequently accessed data can be stored in cold storage on the File Store Service, with Doris automatically retrieving the cold data when needed (though this may incur a slight performance penalty).
Disadvantages of the new system
-
It is difficult to maintain, as it requires significant time to adjust the many configuration parameters (over 100) to ensure the system operates as expected.
-
Users may encounter OOM errors if too many users access the system at the same time, as different queries compete for RAM resources (in this case, some users may encounter errors while others do not, depending on the process and group_account).
-
Data replication between nodes can sometimes lose synchronization due to network issues or other reasons, and the automatic replication retry mechanism may not be successful. In such cases, it is necessary to set up an external worker mechanism for automatic handling (Doris manages a storage unit called Tablet. The metadata on each node records the ETL data into a specific table, and the metadata version gets updated. Doris provides a SQL-based method to handle desynchronization).
-
New versions may occasionally have bugs, so it's recommended to check if the community has reported any issues before deciding to upgrade.
-
Limited support for processing Vietnamese text, with the full-text search feature not performing well in Vietnamese.
-
The servers used are provided by a Vietnamese company, which seems to be using OpenStack, so they can occasionally be unstable. The occasional node disconnections require intervention from the provider. However, due to the high availability feature, Doris can still be used, though performance may be reduced during these periods (node disconnections are not frequent, occurring around once every few months). If the disconnection happens on a BE node, data rebalancing may be required if there are active ETL jobs at that time.
Key lessons from this migration process
-
The bandwidth requirements were not properly estimated, so Doris sometimes exceeds the read capacity when reading data from the old tables stored in GCS.
-
The migration team was not fully dedicated to the task, spending only 70% of their time on the migration and 30% on other responsibilities. This intermittent work led to lower-than-expected performance. (I worked part-time.)
-
For real-time data streams, the recorded storage files are very small in size, so it is necessary to adjust the compaction configuration so that Doris can merge files in groups, which will give better query performance.
-
We spent significant time manually inspecting the data mart tables to determine the appropriate index type. However, this process can be automated by leveraging a metadata management tool like Datahub.
-
The data quality validation process was not thorough enough. We should use a more comprehensive approach combining count, sum, and dimensional checks to ensure high data accuracy.
-
We realized that the old system, built by the management, was designed with extensibility, integration, and migration in mind, so I hardly changed the flow or logic but made the most of the old system. It is a valuable lesson to learn from the legacy system's architecture.
This article does not go into depth on the technical details of the new data lakehouse techniques, and the process of selecting the appropriate technologies is not discussed in detail, either.
Now, the data lakehouse has been used stably by the teams for weeks, and both the CTO and CFO are happy with it. However, it will require more extensive usage to enable a more objective evaluation.
Note: Using BigQuery is still more convenient than Doris, as Doris is an open-source solution and can have some minor issues. Doris requires more complex techniques to ensure a stable cluster, or it will require more effort in cluster maintenance. However, if you use Doris for an extended period and develop a good understanding of how to operate it, the maintenance costs are not particularly high.
Nevertheless, I still prefer using BigQuery. :D
References
-
Debezium: https://debezium.io/
-
Apache Doris: https://doris.apache.org/
-
Tencent blog: https://medium.com/geekculture/tencent-data-engineer-why-we-go-from-clickhouse-to-apache-doris-db120f324290