The author previously presented this topic at the VeloDB Webinar. This article expands on that presentation by providing more detailed comparative information, including test data and in-depth technical explanations:
In the past year, there's an increasing number of users looking to use Apache Doris as an alternative to Elasticsearch, so I'd like to provide an in-depth comparison of the two to serve as a reference for users.
Apache Doris is a real-time data warehouse commonly used for observability, cyber security analysis, online reports, customer profiles, data lakehouse and more. Elasticsearch is more like a search engine, but it is also widely used for data analytics, so there's an overlap in their use cases. The comparison in this post will focus on the real-time analytics capabilities of Apache Doris and Elasticsearch from a user-oriented perspective:
- Open source
- System architecture
- Real-time writes
- Real-time storage
- Real-time queries
Open source
The license decides the level of openness of an open source product, and further decides whether users will be trapped in a vendor lock-in situation.
Apache Doris is operated under the Apache Software Foundation and it is governed by Apache License 2.0. This is a highly liberal open source license. Anyone can freely use, modify, and distribute Apache Doris in open source or commercial projects.
Elasticsearch has undergone several changes in licenses. It was subject to Apache License 2.0 at the very beginning. Then in 2021, it switched to the Elastic License and SSPL, mostly because some cloud service providers were providing Elasticsearch as a managed service. The Elastic company tried to protect its business interests and moved to the Elastic License in order to restrict certain commercial use. And then in 2024, Elasticsearch announced that "Elasticsearch Is Open Source. Again!" by adding the AGPL License. This license has less restrictions on cloud providers.
The difference in licenses reflects the differing ways in which the two open-source projects are managed and operated. Apache Doris is operated under the Apache Software Foundation and adheres to "the Apache Way" and maintains vendor neutrality. It will always be under Apache License and maintain a high level of openness. Elasticsearch is owned and run by the Elastic company, so it is free to change its license based on the changing needs of the company.
System architecture
The system architecture of Apache Doris and Elasticsearch is relevant to how users can deploy them and the software/hardware prerequisites that must be met.
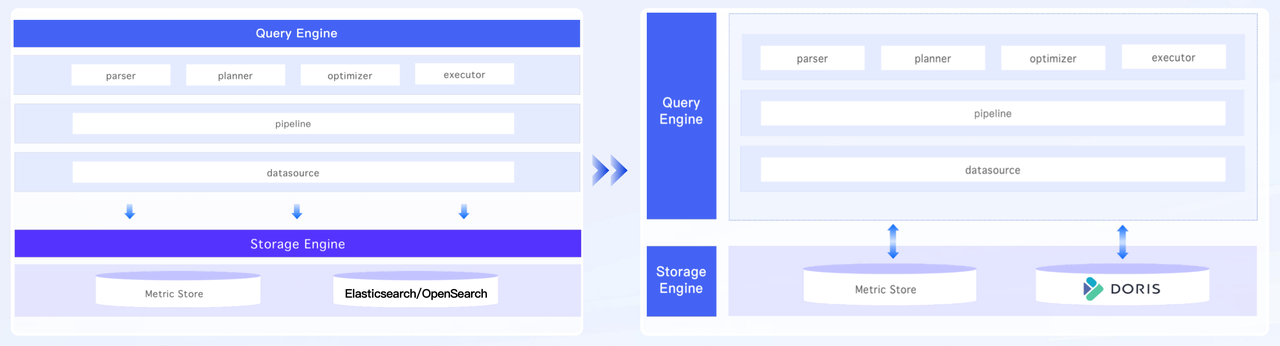
Apache Doris supports various deployment models, especially after the release of verion 3.0. It can be deployed on-premise the traditional way, which means compute and storage are integrated within the same hardware. It can also be deployed with compute and storage decoupled, providing higher flexibility and elasticity.
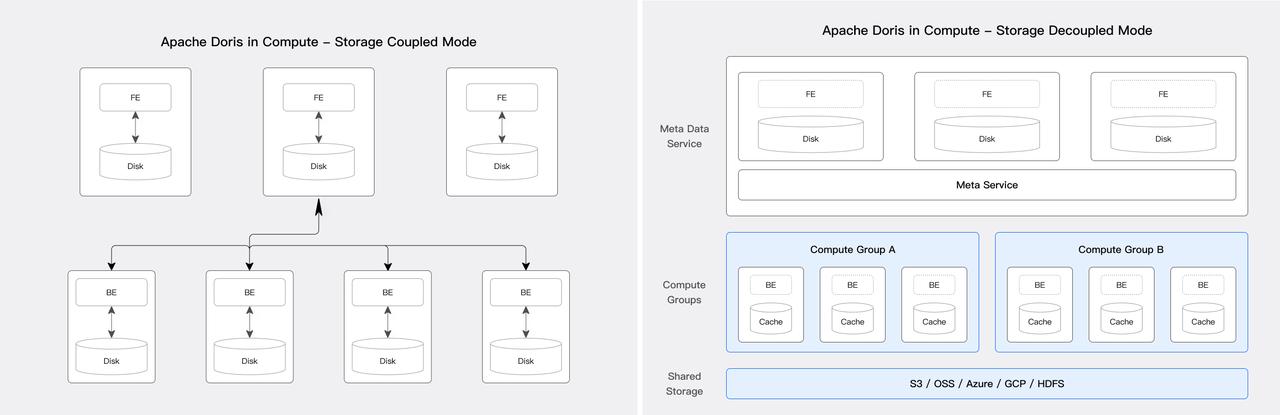
Apache Doris enables the isolation of computing workloads, which makes it well-suited for multi-tenancy. In addition to decoupling compute and storage, it also provides tiered storage so you can choose different storage medium for your hot and cold data.
For workload isolation, Apache Doris provides the Compute Group and Workload Group mechanism.
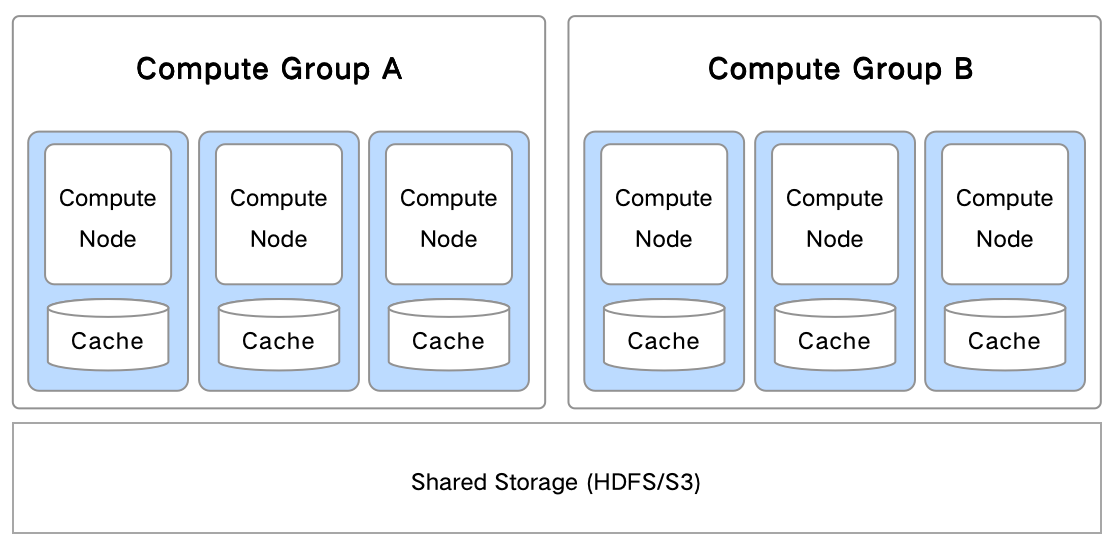
Compute Group is a mechanism for physical isolation between different workloads in a compute-storage decoupled architecture. One or more BE nodes can form a Compute Group.
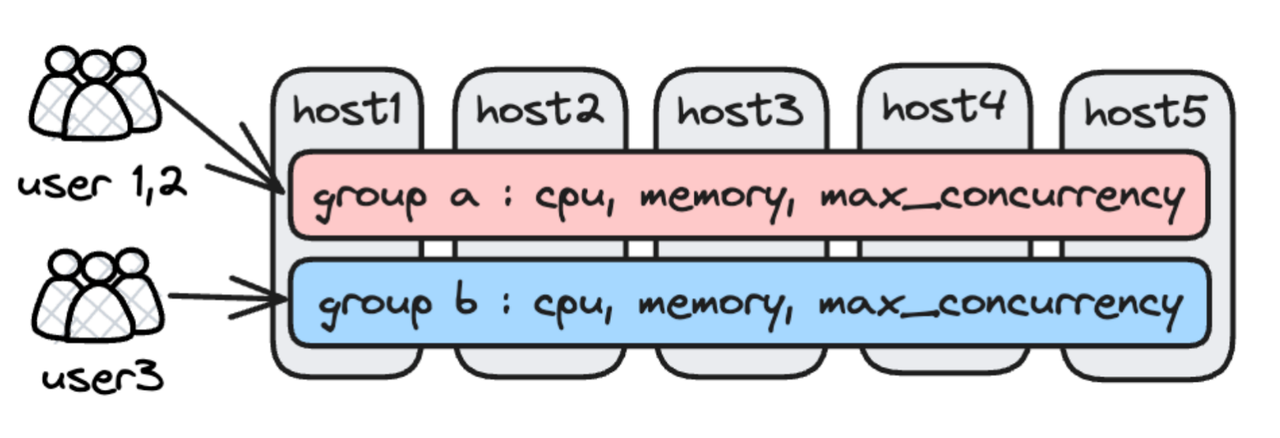
Workload Group is an in-process mechanism for isolating workloads. It achieves resource isolation by finely partitioning or limiting resources (CPU, IO, Memory) within the BE process, which is implemented by Linux CGroup and offers strict hard isolation.
Elasticsearch supports on-premise and cloud deployment. It does not support compute-storage decoupling. Elasticsearch implements workload isolation by Thread Groups, which provides limited soft resource isolation.
Real-time writes
The next step after deploying the system is to write data into it. Apache Doris and Elasticsearch are very different in data ingestion.
Write capabilities
Normally there are two ways to write real-time data into a data system. One is push-based, and the other is pull-based. A push-based method means users actively push the data into the database system, such as via HTTP. A pull-based method, for example, is where database system pulls data from data source such as Kafka message queue.
Elasticsearch supports push-based ingestion, but it requires Logstash to perform pull-based data ingestion, making it less convenient.
As for Apache Doris, it supports both push-based method (HTTP Stream Load) and pull-based method (Routine Load from Kafka, Broker Load from object storage and HDFS). In addition, output plugins for Logstash and Beats are available to enable seamless data ingestion from Logstash or Beats into Doris.
In addition, Doris provides a special write transaction mechanism. By setting a label for a batch of data through the Load API, attempting to re-load a label that has been successfully load before will result in an error, thereby achieving data deduplication. This mechanism ensures that data is written without loss or duplication without relying on the uniqueness of primary keys at the storage layer. Additionally, having a unique label for each batch of data offers better performance compared to having a unique primary key for each individual record.
Write performance
Apache Doris, as a real-time data warehouse, supports real-time data writes and updates. One of the standout features of Doris is its incredibly high write throughput. This is because the Doris community has put a lot of effort in optimizing it for high-throughput writes such as vertorized writting and single replica indexing.
On the other hand, the low write throughput of Elasticsearch is a well-known pain point. This is due to Elasticsearch's needs to generate complex inverted index on multiple replicas, causing a lot of overheads.
We compare the write performance of Doris and Elasticsearch using Elasticsearch's official benchmark httplogs, under the same hardware resources and storage schema (including field types and inverted indexes). The test environment and results are as follows:
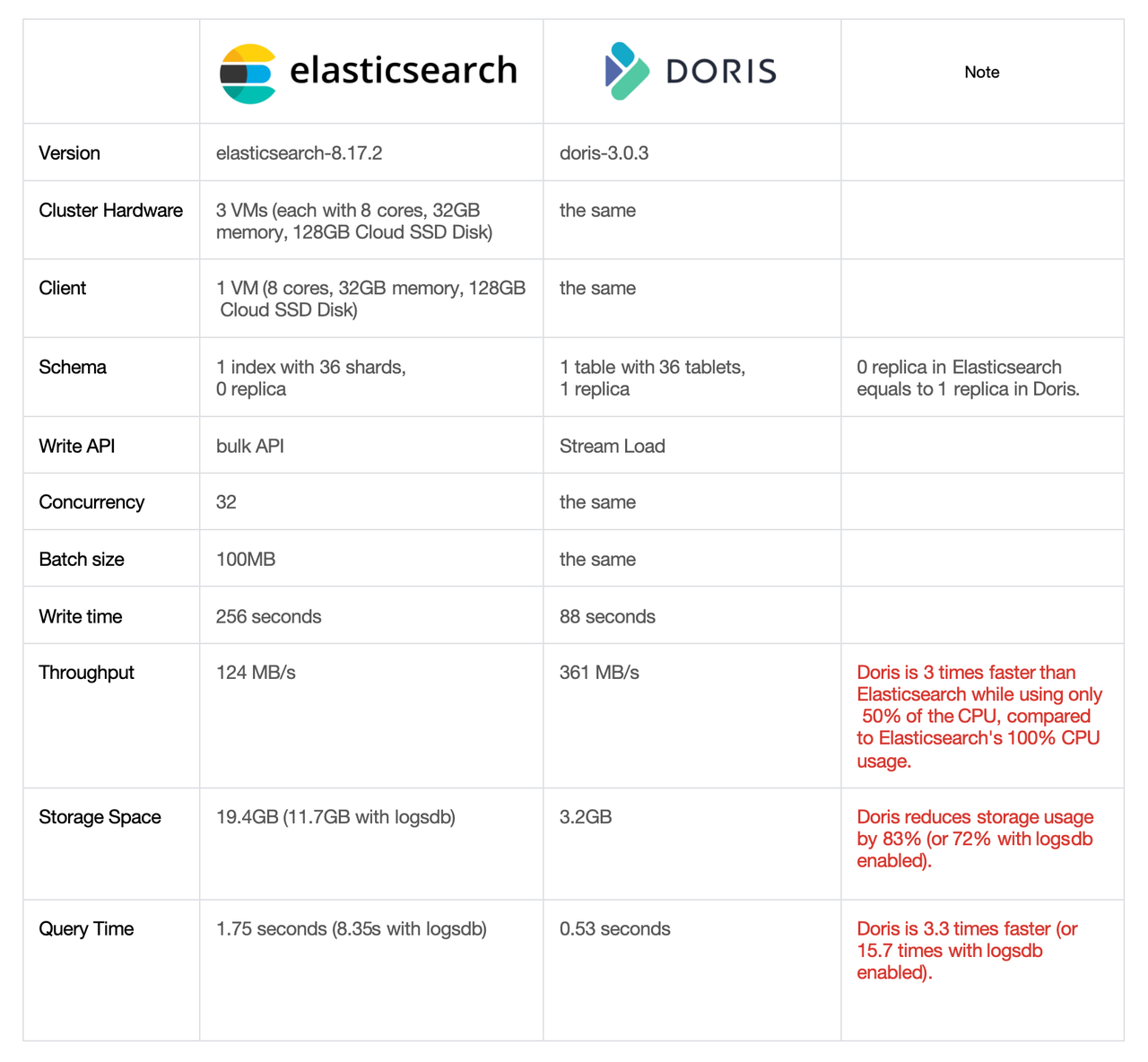
Under the premise of creating the same inverted index, Apache Doris delivers a much higher write throughput than Elasticsearch. This is due to some key advancements in performance optimization, including:
- Doris is implemented in C++, which is more efficient than Elasticsearch's Java implementation.
- The vectorized execution engine of Doris fully utilizes CPU SIMD instructions to accelerate both data writing and inverted index building. Its columnar storage also facilitates vectorized execution.
- The inverted index of Doris is simplified for real-time analytics scenarios, eliminating unnecessary storage structures such as forward indexes and norms.
Real-time storage
Storage format and cost
As a real-time data warehouse, Doris adheres to the typical relational database model, with a storage hierarchy that includes catalog, database, and table levels. A table consists of one or more columns, each with its own data type, and indexes can be created on the columns.
By default, Doris stores tables in a columnar format, meaning that data for a single column is stored in contiguous physical files. This not only achieves a high compression ratio but also ensures high query efficiency in analysis scenarios where only certain columns are accessed, as only the required data is read and processed. Additionally, Doris supports an optional row storage format to accelerate detailed point queries.
In Elasticsearch, data is stored in Lucene using a document model. In this model, an Elasticsearch index is equivalent to a database table, the index mapping corresponds to the database table schema, and fields within the index mapping are akin to columns in a database, each with its own type and index type.
By default, Elasticsearch uses row-based storage (the _source field), where each field has an associated inverted index created for it, but it also supports optional columnar storage (docvalue). Generally, row-based storage is essential in Elasticsearch because it lays the foundation for raw detailed data queries.
Storage space consumption, or more straightforward, storage cost, is a big concern for users. This is another pain point of Elasticsearch - it creates huge storage costs.
Apache Doris community have made a lot of optimizations and successfully reduced the storage cost significantly. We have put a lot of work to simplify inverted index, which is supported in Doris since version 2.0, and it now takes up much less space. Doris supports the ZSTD algorithm, which is much more efficient than GZIP and LZ4, and it can reach a data compression ratio of 5:1 ~ 10:1. Since the compression ratio of Elasticsearch is usually about 1.5:1, Doris is 3~5 times more efficient than Elasticsearch in data compression.
As demonstrated in the httplogs test results table above, 32GB of raw data occupies 3.2GB in Doris, whereas Elasticsearch defaults to 19.4GB. Even with the latest logsdb optimization mode enabled, Elasticsearch still consumes 11.7GB. Compared to Elasticsearch, Doris reduces storage space by 83% (73% with logsdb enabled).
Table model
Apache Doris provides three data models. As for Elasticsearch, I put it as "one and two half" models because it only provides limited support for certain data storage models. I will get to them one by one.
-
The first is the Duplicate model, which means it allows data duplication. This is suitable for storing logs. Both Doris and Elasticsearch support this model.
-
The second is the primary key model. It works like OLTP databases, which means the data will be deduplicated by key. The primary key model in Doris provides high performance and many user-friendly features. Just like many databases, you can define one or multiple fields as the primary and unique key.
-
However, in Elasticsearch, you can only use a special field _id as the unique identifier for a document (a row in database). Unlike database primary key, there are many limitations for it.
-
The
_idfield can not be used for aggregation or sorting -
The
_idfield can not be larger than 512 bytes -
The
_idfield can not be multiple fields, so you will need to combine the multiple fields into one before you can use them as the primary key, but the length of the combined _id can still not exceed 512 bytes.
-
-
The third is the aggregation model, which means data will be aggregated or rolled up.
In its early stages, Elasticsearch provided the rollup feature through the commercial X-Pack plugin, allowing users to create rollup jobs that configured dimensions, metric fields, and aggregation intervals for rollup indexes based on a base index. However, X-Pack rollup had several limitations:
- Data Asynchrony: Rollup jobs ran in the background, meaning the data in the rollup index was not synchronized in real time with the base index.
- Specialized Query Requirement: Queries targeting rolled-up data required dedicated rollup queries, and users had to manually specify the rollup index in their queries.
Perhaps these reasons explain why Elasticsearch has deprecated the use of rollup starting in version 8.11.0 and now recommends downsampling as an alternative. Downsampling eliminates the need to specify a separate index and simplifies querying, but it also comes with its own constraints:
- Time-Series Exclusive: Downsampling is only applicable to time-series data, relying on time as the primary dimension. It cannot be used for other data types, such as business reporting data.
- Index Replacement: A downsampled index replaces the original index, meaning aggregated data and raw data cannot coexist.
- Read-Only: Downsampling can only be performed on the original index after it transitions to a read-only state. Data actively being written (e.g., real-time ingestion) cannot undergo downsampling.
As a real-time data warehouse excelling in aggregation and analytics, Doris has supported aggregation capabilities since its early use cases in online reporting and analytics. It offers two flexible mechanisms:
- Aggregation Table Model:
- Data is directly aggregated during ingestion, eliminating the storage of raw data.
- Only aggregated results are stored, drastically reducing storage costs.
- Aggregated Materialized Views / Rollup:
- Users can create aggregated materialized views on a base table. Data is written to both the base table and the materialized view simultaneously, ensuring atomic and synchronized updates.
- Queries target the base table, and the query optimizer automatically rewrites queries to leverage the materialized view for accelerated performance.
This design ensures real-time aggregation while maintaining query flexibility and efficiency in Doris.
Flexible schema
In most cases, especially for online business scenarios, users often need to update or modify the data schema. Elasticsearch supports flexible schema, but it only allows users to dynamically add columns.
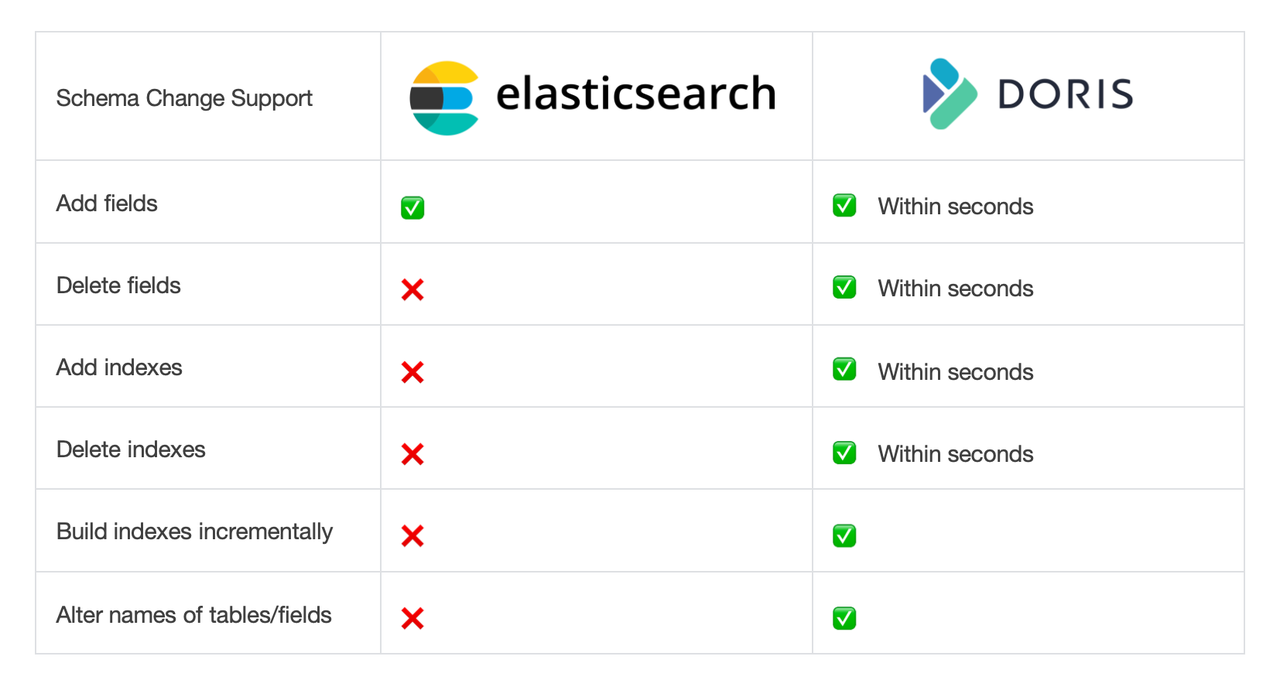
When you write JSON data into Elasticsearch, if the data contains a new field which is not in index mapping, Elasticsearch will create a new field in the schema through dynamic mapping, so you don't need to change the schema beforehand, like you have to do in traditional databases. However, in Elasticsearch, users cannot directly delete a field of the schema. For that, you will need a reindex operation that reads and writes the entire index in Elasticsearch.
In addition, Elasticsearch does not allow adding index for an already existed field. Imagine that you have 100 fields in a schema, and you have created inverted index for 10 of them, and then some days later, you want to add inverted index for another 5 fields, but no, you can't do that in Elasticsearch. Likewise, deleting index for a field is not allowed either.
As a result, to avoid such troubles, most Elasticsearch users will just create inverted index for all of their fields, but that causes much slower data writing and much larger storage usage.
Also, Elasticsearch does not allow you to modify your index names or your field names. To sum up, if you need to make any changes to your data other than adding a field, you will need to re-index everything. That's a highly resource-intensive and time-consuming operation.
What about Apache Doris? Doris supports all these schema changes. You can add or delete fields and indexes as you want, and you can change the name of any table or field easily. Doris can finish these changes within just a few milliseconds. Such flexibility will save you a lot of time and resource, especially when you have changing business needs.
Real-time queries
We break down the real-time querying of Elasticsearch and Apache Doris into three dimensions: usability, query capabilities, and performance.
Usability
One key aspect of usability is reflected in the user interface.
The Doris SQL interface is designed to maintain protocol and syntax compatibility with MySQL. It even does not have its own client or JDBC driver, allowing the use of MySQL’s client and JDBC driver directly. This is a big convenience for many users familiar with MySQL. In fact, this choice was made early in the original design of Doris to make it more user-friendly. Since MySQL is the most widely used open-source OLTP database, Doris is designed to complement MySQL, creating the best practice for combining OLTP (MySQL) with OLAP (Doris). This allows engineers and data analysts to work seamlessly within a single interface and set of syntax, covering both transactional and analytical workloads.
On the other hand, Elasticsearch has its own Domain Specific Language (DSL), which is originally designed for searching. This DSL is part of the Elasticsearch ecosystem, it often requires engineers to invest a lot of time and effort to fully understand and use the DSL effectively.
Let's take a look at one example:

Imagine we want to search for a particular keyword within a particular time range, and then group and order the data by time interval to visualize it as a trend chart.
In Doris, this can be done with only 7 lines of SQL. However, in Elasticsearch, the same process requires 30 lines.
And it's not just about the code complexity. I believe many of you may find this relatable: The first attempt to learn Elasticsearch's DSL is quite challenging. And even after gaining familiarity with it, crafting a query often requires frequent reference to documentation and examples. Due to its inherent complexity, writing DSL queries from scratch remains a challenging task. In contrast, SQL is simple, clear, and highly structured. Most engineers can easily write a query like this without much effort.
Query capabilities
Elasticsearch is good at searching. As its name suggests, it was built for search. But beyond search and aggregation queries, it doesn't support complex analytical queries, such as multi-table JOIN.
Apache Doris is a general-purpose data warehouse. It provides strong support for complex analytics, including multi-table JOIN, UDF, subquery, window function, logic view, materialized view, and data lakehouse. And Doris has been improving its searching capabilities since version 2.0. We have introduced inverted index and full-text search, so it is getting increasingly competitive in this area.
Search
While this article focuses on real-time analytics scenarios, we have chosen not to overlook Elasticsearch’s core strength: its search capabilities.
Elasticsearch, renowned for its search performance, leverages the Apache Lucene library under the hood. It provides two primary indexing structures:
- Inverted indexes for text fields.
- BKD-Tree indexes for numeric, date, and geospatial data.
Elasticsearch supports the following search paradigms:
- Exact Matching: equality or range queries for numeric, date, or non-tokenized string fields (keyword), powered by BKD-Tree indexes (numeric/date) or non-tokenized inverted indexes (exact term matches).
- Full-Text Search: keyword, phrase, or multi-term matching. During ingestion, text is split into tokens using a configurable tokenizer. Queries match tokens, phrases, or combinations (e.g.,
"quick brown fox"). Elasticsearch supports some advanced full-text search features, such as relevance scoring, auto-completion, spell-checking, and search suggestions. - Vector Search based on ANN index.
Doris also supports a rich set of indexes to accelerate queries, including prefix-sorted indexes, ZoneMap indexes, BloomFilter indexes and N-Gram BloomFilter indexes.
Starting from version 2.0, Doris has added inverted indexes and BKD-Tree indexes to support exact matching and full-text search. Vector search is currently under development and is expected to be available within the next six months.
There are some differences between the indexes of Apache Doris and Elasticsearch:
- Diverse indexing strategies: Doris does not rely solely on inverted indexes for query acceleration. It offers different indexes for different scenarios. ZoneMap, BloomFilter, and N-Gram BloomFilter indexes are skip indexes that accelerate analytical queries by skipping non-matching data blocks based on
WHEREconditions. The N-Gram BloomFilter index is specifically optimized forLIKE-style fuzzy string matching. Inverted index and Prefix-sorted indexes are point query indexes that speed up point queries by locating which rows satisfy the WHERE conditions through the index and directly read those rows. - Performance centric design: Doris prioritizes speed and efficiency over advanced search features. To achieve faster index building and query performance (see the Query Performance section in the following), it omits certain complex functionalities of inverted indexes at present, such as relevance scoring, auto-completion, spell-checking, and search suggestions. Since there are more critical in document or web search scenarios, which are not Doris’ primary focus on real-time analytics.
For exact matching and common full-text search requirements, such as term, range, phrase, multi-field matching, Doris is fully capable and reliable in most use cases. For complex search needs (e.g., relevance scoring, auto-completion, spell-checking, or search suggestions), Elasticsearch remains the more suitable choice.
Aggregation
Both Elasticsearch and Doris support a wide range of aggregation operators, including:
- Basic aggregations:
MIN,MAX,COUNT,SUM,AVG. - Advanced aggregations:
PERCENTILE(quantiles),HISTOGRAM(bucketed distributions). - Aggregation modes: Global aggregation, key-based grouping (e.g.,
GROUP BY).
However, their approaches to aggregation analysis differ significantly in the following aspects:
1. Query syntax and usability: Doris uses standard SQL syntax (GROUP BY clauses + aggregation functions), making it intuitive for analysts and developers familiar with SQL. Elasticsearch relies on a custom Domain-Specific Language (DSL) with concepts like metric agg, bucket agg, and pipeline agg. Complexity increases with nested or multi-layered aggregations, requiring steeper learning curves.
2. Result accuracy: Elasticsearch outputs inaccurate approximate result for many aggregation types by default. Aggregations (e.g., terms agg) are executed per shard, with each shard returning only its top results (e.g., top 10 buckets). These partial results are merged globally, leading to potentially inaccurate final outputs. As a serious OLAP database, Doris ensures exact results by processing full datasets without approximations.
3. Query Performance: Doris demonstrates significant performance advantages over Elasticsearch in aggregation-heavy OLAP workloads like those on ClickBench (see more in the Query performance section bellow).
JOIN
Elasticsearch does not support JOIN, making it unable to execute common benchmarks like TPC-H or TPC-DS. Since JOINs are critical in data analysis, Elasticsearch provides some complex workarounds with significant limitations:
- Parent-child relationships and has_child / has_parent queries: Simulate JOINs by establishing parent-child relationships within a single index. Child documents store the parent document’s ID.
has_childqueries first find matching child documents, then retrieve their parent documents via the stored parent IDs.has_parentqueries reverse this logic. It's complex and Elasticsearch explicitly warns against equating this approach to database-style JOINs.We don’t recommend using multiple levels of relations to replicate a relational model. Each level of relation adds an overhead at query time in terms of memory and computation. For better search performance, denormalize your data instead.
- Terms lookup: Similar to an IN-subquery by fetching a value list from one index and using it in a
termsquery on another. It's only suitable for large-table-to-small-table JOINs (e.g., filtering a large dataset using a small reference list), but performs very poorly for large-table-to-large-table JOINs due to scalability issues.
Doris provides comprehensive support for JOIN operations, including:
- INNER JOIN
- CROSS JOIN
- LEFT / RIGHT / FULL OUTER JOIN
- LEFT / RIGHT SEMI JOIN
- LEFT / RIGHT ANTI JOIN
Further more, Doris’ query optimizer adaptively selects optimal execution plans for JOIN operations based on data characteristics and statistics, including:
- Small-large table JOIN:
- Broadcast JOIN: The smaller table is broadcast to all nodes for local joins.
- Large-large table JOIN:
- Bucket Shuffle JOIN: Used when the left table’s bucketing distribution aligns with the JOIN key.
- Colocate JOIN: Applied when both the left and right tables share identical bucketing distributions with the JOIN keys.
- Runtime Filter: Reduces data scanned in the left table by pushing down predicates from the right table using runtime-generated filters.
This intelligent optimization ensures efficient JOIN execution across diverse data scales and distributions, including TPC-H and TPC-DS benchmarks.
Lakehouse
Data warehouses addresses the need for fast data analysis, while data lakes are good at data storage and management. The integration of them, known as "lakehouse", is to facilitate the seamless integration and free flow of data between the data lake and data warehouse. It enables users to leverage the analytic capabilities of the data warehouse while harnessing the data management power of the data lake.
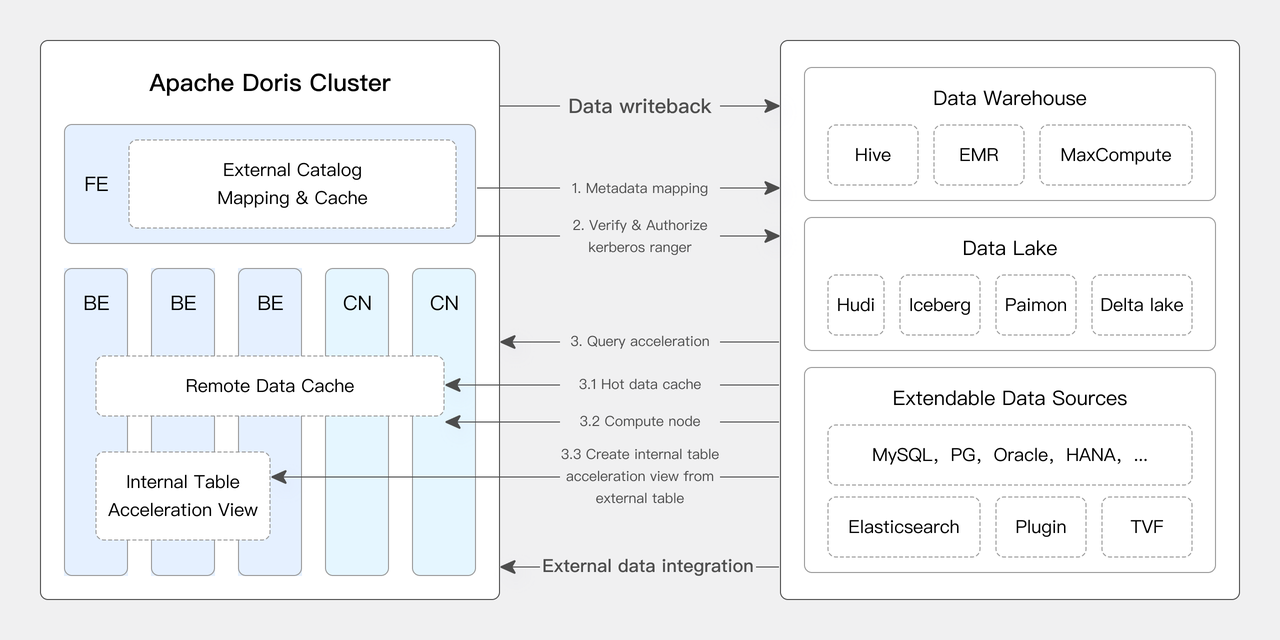
Apache Doris can work as a data lakehouse with its Multi Catalog feature. It can access databases and data lakes including Apache Hive, Apache Iceberg, Apache Hudi, Apache Paimon, LakeSoul, Elasticsearch, MySQL, Oracle, and SQLServer. It also supports Apache Ranger for privilege management.
Elasticsearch does not support querying external data, and of course, it does not support lakehouse either.
Query performance
Apache Doris has been extensively optimized for multiple scenarios, so it can deliver high performance in many use cases. For example, Doris can achieve tens of thousands of QPS for high-concurrency point queries, and it delivers industry-leading performance in aggregation analysis on a global scale.
Elasticsearch is good at point queries (retrieving just a small amount of data). However, it might struggle with complex analytical workloads.
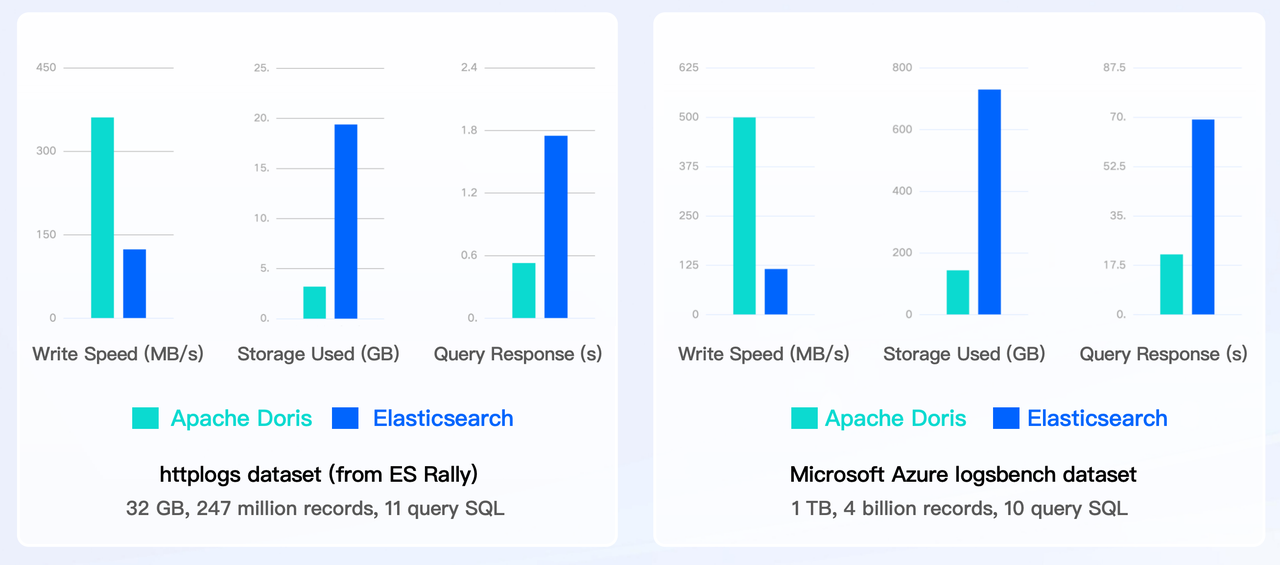
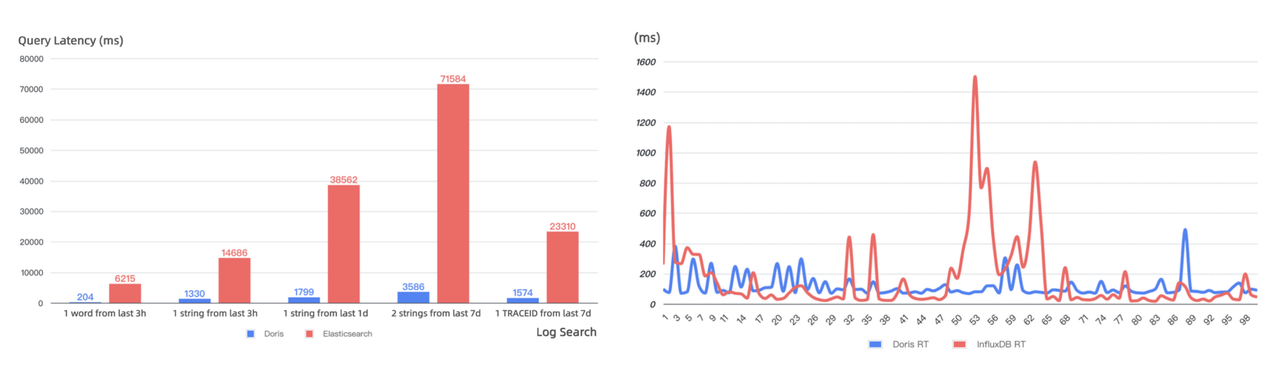
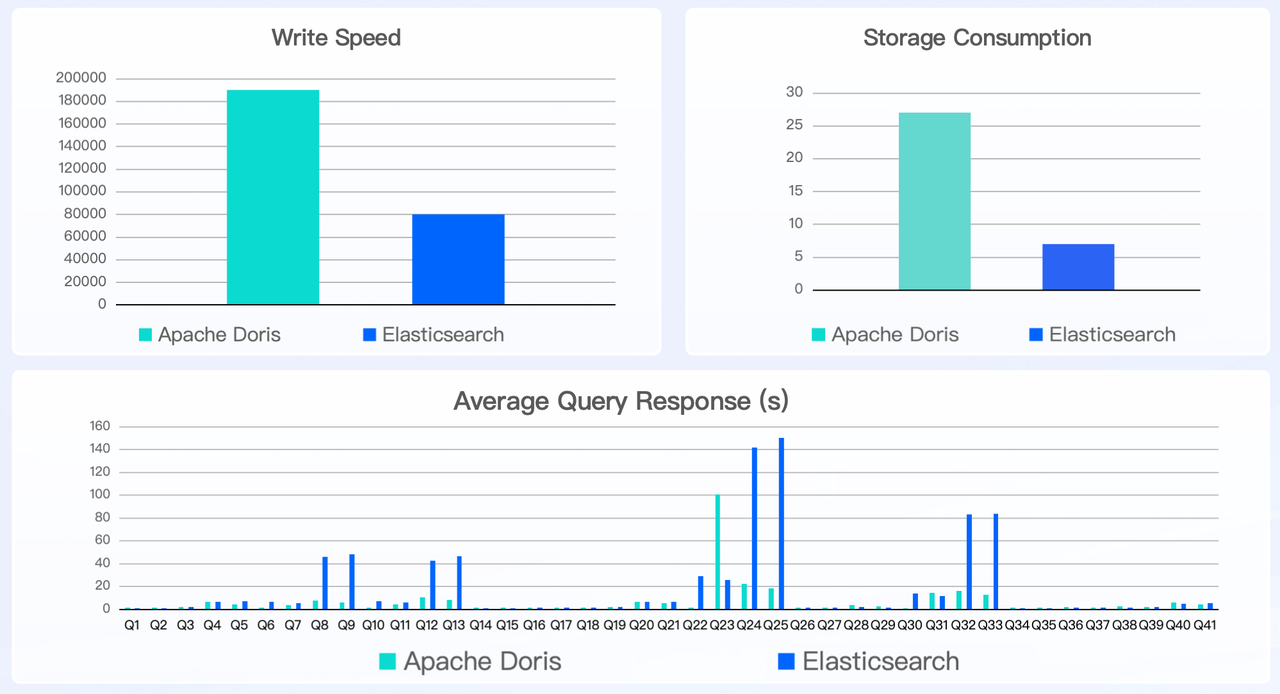
Elasticsearch httplogs and the Microsoft Azure logsbench are benchmarks for log storage and search. Both tests show that Doris is about 3~4 times faster than Elasticsearch in data writing, but only uses 1/6~1/4 of the storage space that Elasticsearch uses. Then for data queries, Doris is more than 2 times faster than Elasticsearch.
ClickBench is a benchmark created and maintained by the ClickHouse team to evaluate the performance of analytical databases. It results show that Apache Doris delivers out-of-the-box query performance 21 times faster than Elasticsearch and 6 times faster than a fine-tuned Elasticsearch.

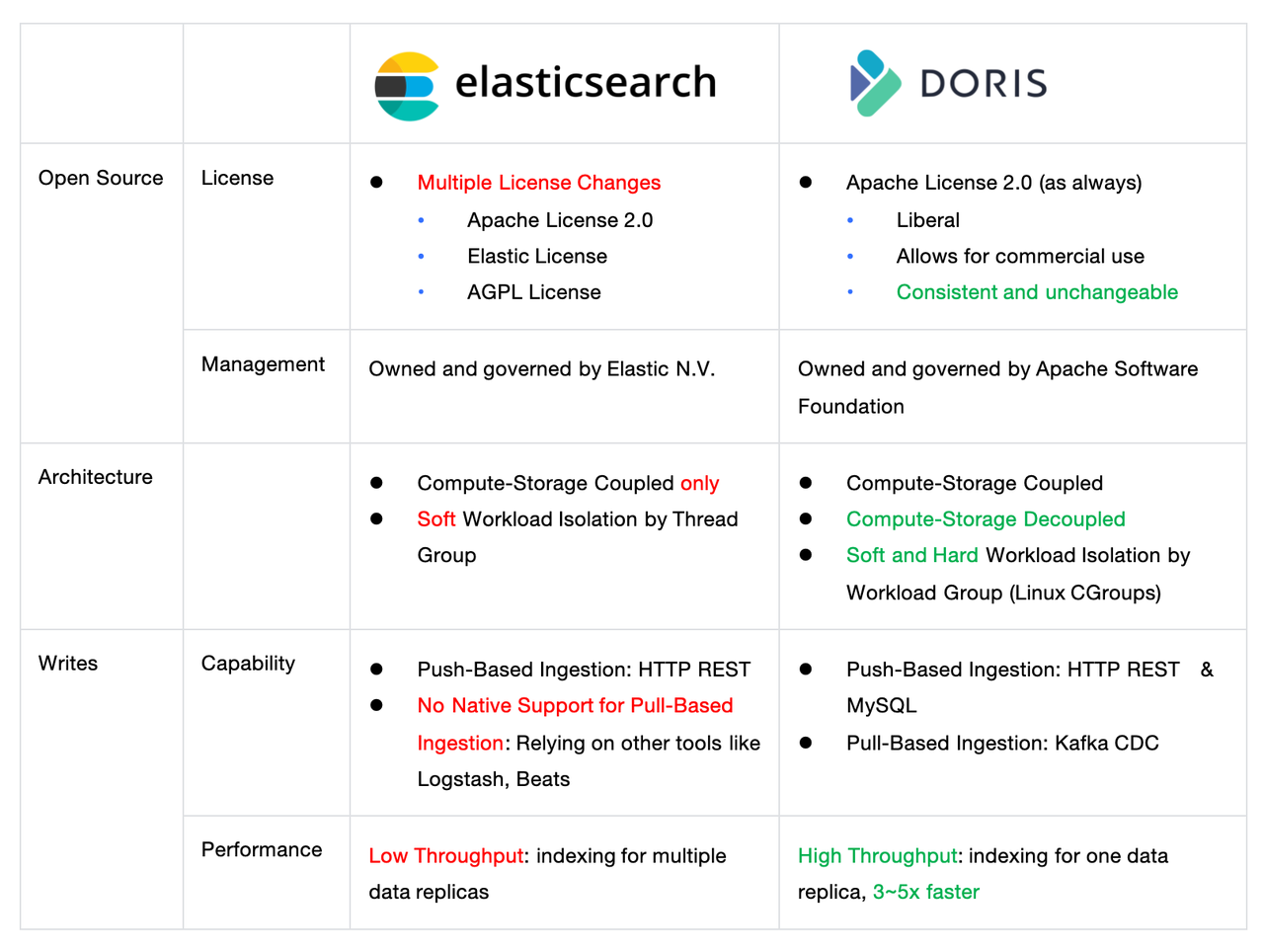
Comparison Summary
In summary, Doris follows Apache License 2.0, which is a highly open license to ensure that Doris remains truly open and will continue to uphold such openness in the future.
Secondly, Doris supports both compute-storage coupled and decoupled mode, while Elasticsearch only supports the former, which enable more powerful elasticity and resource isolation.
Thirdly, Doris provides high performance in data ingestion. It is usually 3~5 times faster than Elasticsearch.
In terms of storage, compared to Elasticsearch, Doris can reduce storage costs by 70% or more. It is also 10 times faster than Elasticsearch in data updates.
As for data queries, Doris outperforms Elasticsearch by a lot. It also provides analytic capabilities that Elasticsearch does have, including multi-table JOIN, materialized views, and data lakehouse.

Use cases
Many users have replaced Elasticsearch with Apache Doris in their production environments and received exciting results. I will introduce some user stories from the fields of observability, cyber security, and real-time business analysis.
Observability
User A: a world-famous short video provider
- Daily incremental data: 800 billion rows (500 TB)
- Average write throughput: 10 million row/s (60GB/s)
- Peak write throughput: 30 million row/s (90GB/s)
Apache Doris supports logging and tracing data storage for this tech giant and meets the data import performance requirements for nearly all use cases within the company.
User B: NetEase - one of the World's Highest-Yielding Game Companies
- Replacing Elasticsearch with Apache Doris for log analysis: reducing storage consumption by 2/3 and achieving 10X query performance
- Replacing InfluxDB with Apache Doris for time-series data analysis: saving 50% of server resources and reducing storage consumption by 67%
User C: an observability platform provider
Apache Doris offers a special data type, VARIANT, to handle semi-structured data in log and tracing, reducing costs by 70% and delivering 2~3 times faster full-text search performance compared to the Elasticsearch-based solution.
Cyber security
User A: QAX - a listed company & leading cyber security leader
The Doris-based security logging solution uses 40% less storage space, delivers 2X faster write performance, and supports full-text search, aggregation analysis, and multi-table JOIN capabilities in one database system.
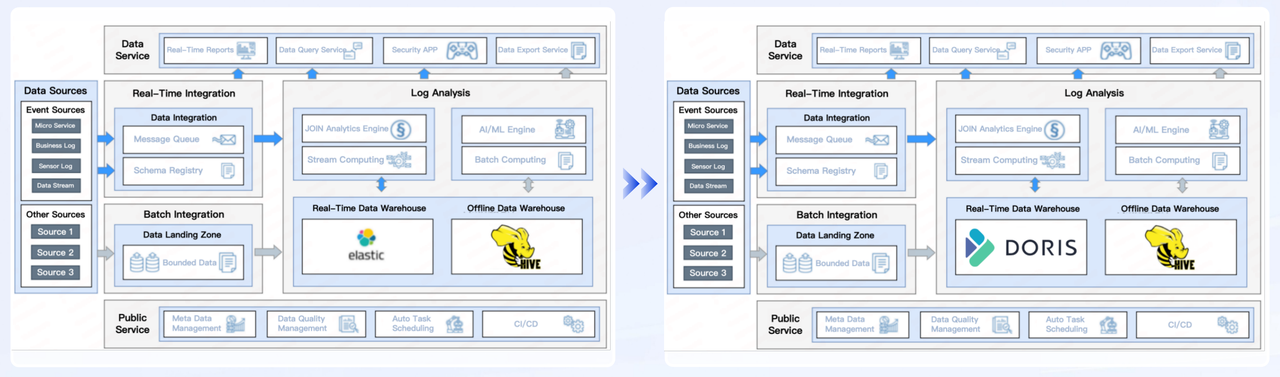
User B: a payment platform with nearly 600 million registered users
As a unified security data storage solution, Apache Doris delivers 4X faster write speeds, 3X better query performance, and saves 50% storage space compared to the previous architecture with diverse tech stacks using Elasticsearch, Hive and Presto.
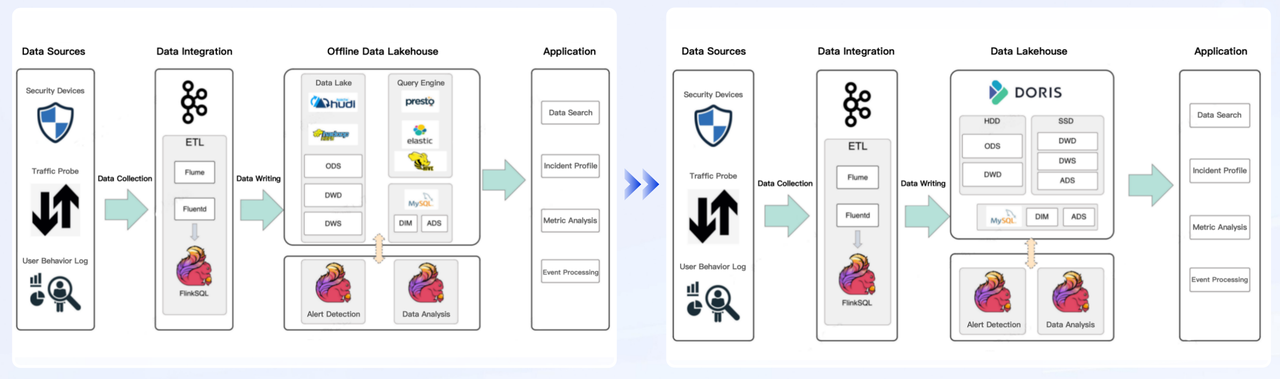
User C: a leading cyber security solution provider
Compared to Elasticsearch, Doris delivers 2 times faster write speeds, 4 times better query performance, and a 4 times data compression ratio.
Business analysis
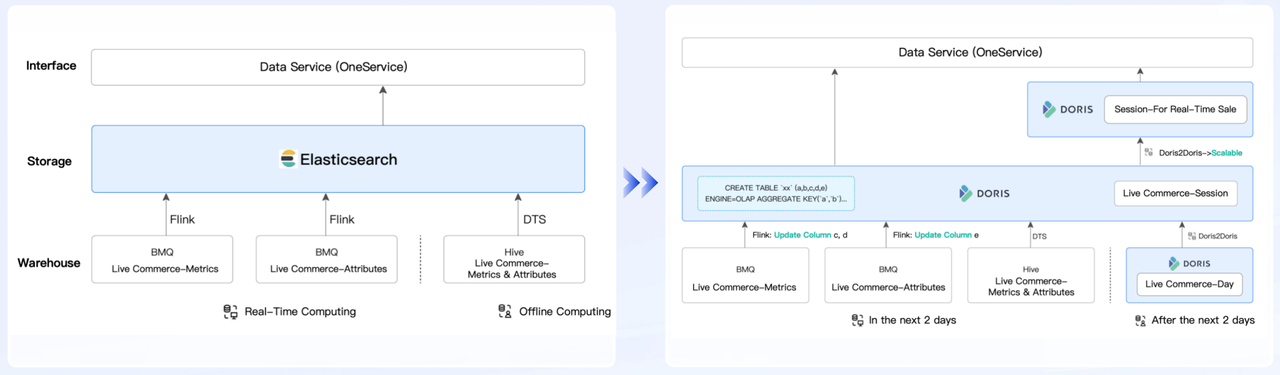
User A: a world-leading live e-commerce company
The user previously relied on Elasticsearch to handle online queries for their live stream detail pages, but they faced big challenges in cost and concurrency. After migrating to Apache Doris, they achieve:
- 3 times faster real-time writes: 30w/s -> 100w/s
- 4 times higher query concurrency: 500QPS -> 2000QPS
User B: Tencent Music Entertainment
Previously, TME content library used both Elasticsearch and ClickHouse to meet their needs for data searching and analysis, but managing two separate systems was complex and inefficient. With Doris, they are able to unify the two systems into one single platform to support both data searching and analysis. The new architecture delivers 4X faster write speeds, reduces storage costs by 80%, and supports complex analytical operations.

User C: a web browser provider with 600 million users
After migrating to Apache Doris for a unified solution for log storage and report analysis, the company doubled its aggregation analysis efficiency, reduced storage consumption by 60%, and cut SQL development time by half.
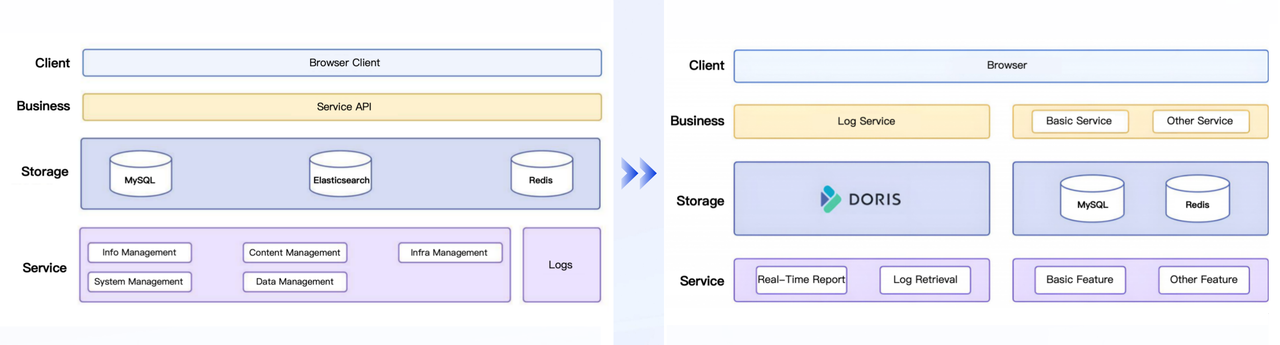
Taking Apache Doris to the next level
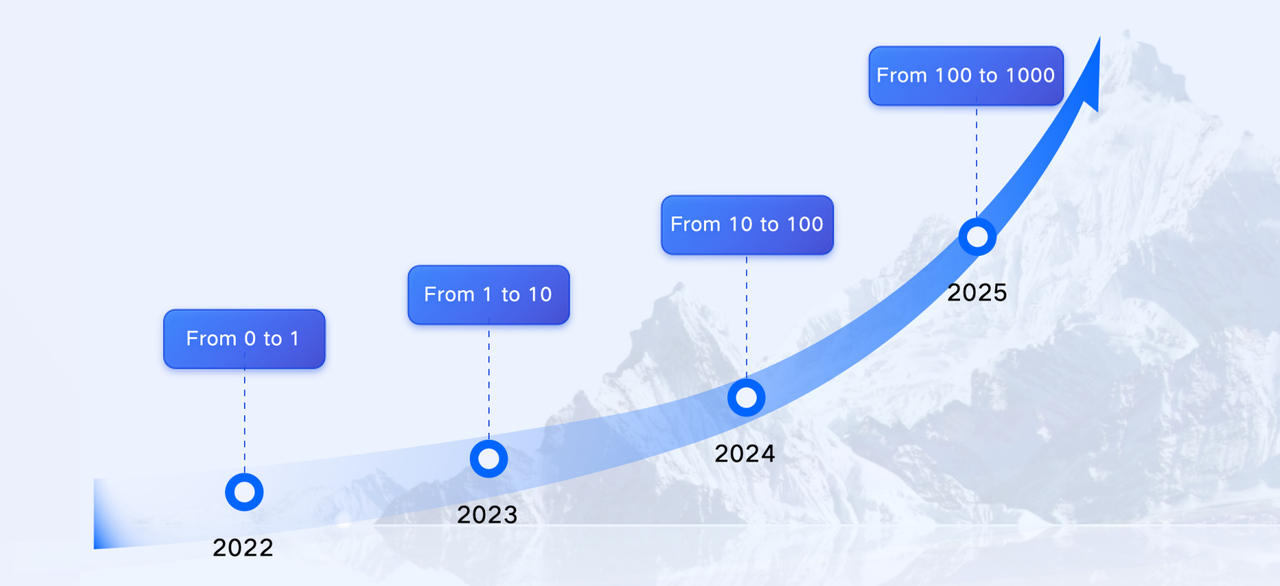
For the Apache Doris community developers, the path to making Doris good enough to replace Elasticsearch wasn't easy. In 2022, we started adding inverted index capabilities to Doris. At that time, this decision was met with skepticism. Many viewed inverted indexes as a feature exclusive to Elasticsearch, a domain few in the industry dared to venture into. Nevertheless, we went with it, and today we can confidently say that we have succeeded.
In 2022, we developed this feature from the ground up, and after a year of dedicated effort, we open-sourced it. Initially, we had only one user, QAX, who was willing to test and adopt the feature. We are deeply grateful to them for their early support during this pivotal stage.
By 2023, the value of Doris with inverted indexes became increasingly evident, leading to broader adoption by about 10 companies.
The growth momentum has continued, and as of 2024, we are experiencing rapid expansion, with over 100 companies now leveraging Doris to replace Elasticsearch.
Looking ahead, I am very much looking forward to what 2025 will bring. This progress, advancing from the ground up to such significant milestones, has been made possible by the incredible support from the Doris community users and developers. We encourage everyone to join the Apache Doris Slack community and join the dedicated channel #elasticsearch-to-doris, where you can receive technical assistance, stay updated with the latest news about Doris, and engage with more Doris developers and users.
More on Apache Doris:
- Apache Doris for log and time series data analysis in NetEase, why not Elasticsearch and InfluxDB?
- From Elasticsearch to Apache Doris: upgrading an observability platform
- Log Analysis: How to Digest 15 Billion Logs Per Day and Keep Big Queries Within 1 Second
- Replacing Apache Hive, Elasticsearch and PostgreSQL with Apache Doris
- Log Analysis: Elasticsearch VS Apache Doris
- A Deep Dive into Inverted Index in Apache Doris
- VARIANT in Apache Doris 2.1.0: a new data type 8 times faster than JSON for semi-structured data analysis
Connect with me on Linkedin
Apache Doris on GitHub
Apache Doris Website


