As much as we say Apache Doris is an all-in-one data platform that is capable of various analytics workloads, it is always compelling to demonstrate that by real use cases. That's why I would like to share this user story with you. It is about how they leverage the capabilities of Apache Doris in reporting, customer tagging, and data lake analytics and achieve high performance.
This fintech service provider is a long-term user of Apache Doris. They have almost 10 clusters for production, hundreds of Doris backend nodes, and thousands of CPU Cores. The total data size is near 1 PB. Every day, they have hundreds of workflows running simultaneously, receive almost 10 billion new data records, and respond to millions of data queries.
Before migrating to Apache Doris, they used ClickHouse, MySQL, and Elasticsearch. Then frictions arise from their ever-enlarging data size. They found it hard to scale out the ClickHouse clusters because there were too many dependencies. As for MySQL, they had to switch between various MySQL instances because one MySQL instance had its limits and cross-instance queries were not supported.
Reporting
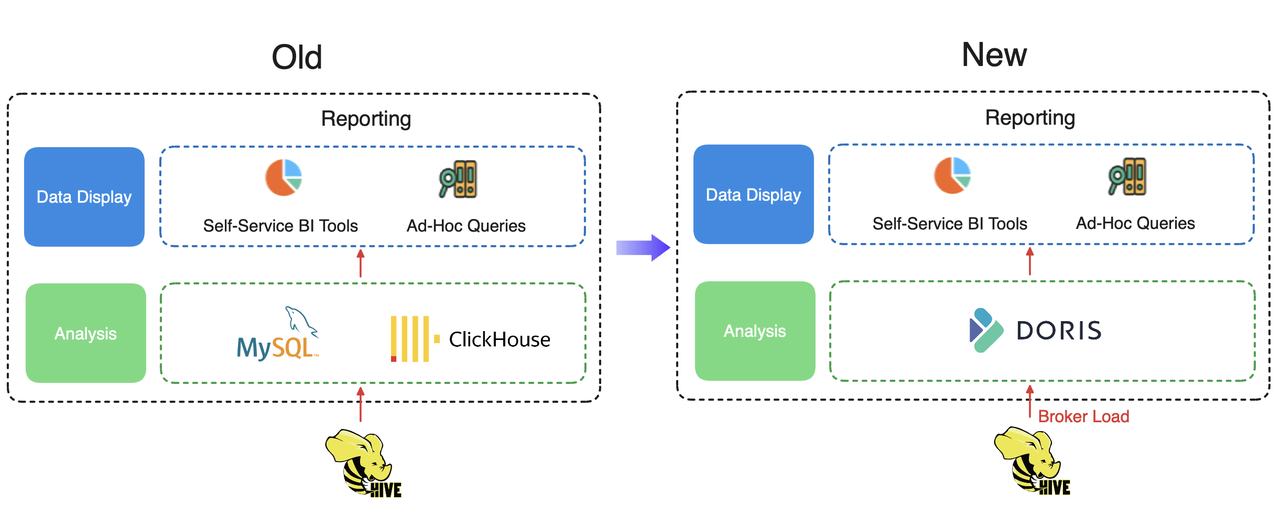
From ClickHouse + MySQL to Apache Doris
Data reporting is one of the major services they provide to their customers and they are bound by an SLA. They used to support such service with a combination of ClickHouse and MySQL, but they found significant fluctuations in their data synchronization duration, making it hard for them to meet the service levels outlined in their SLA. Diagnosis showed that it was because the multiple components add to the complexity and instability of data synchronization tasks. To fix that, they have used Apache Doris as a unified analytic engine to support data reporting.
Performance improvements
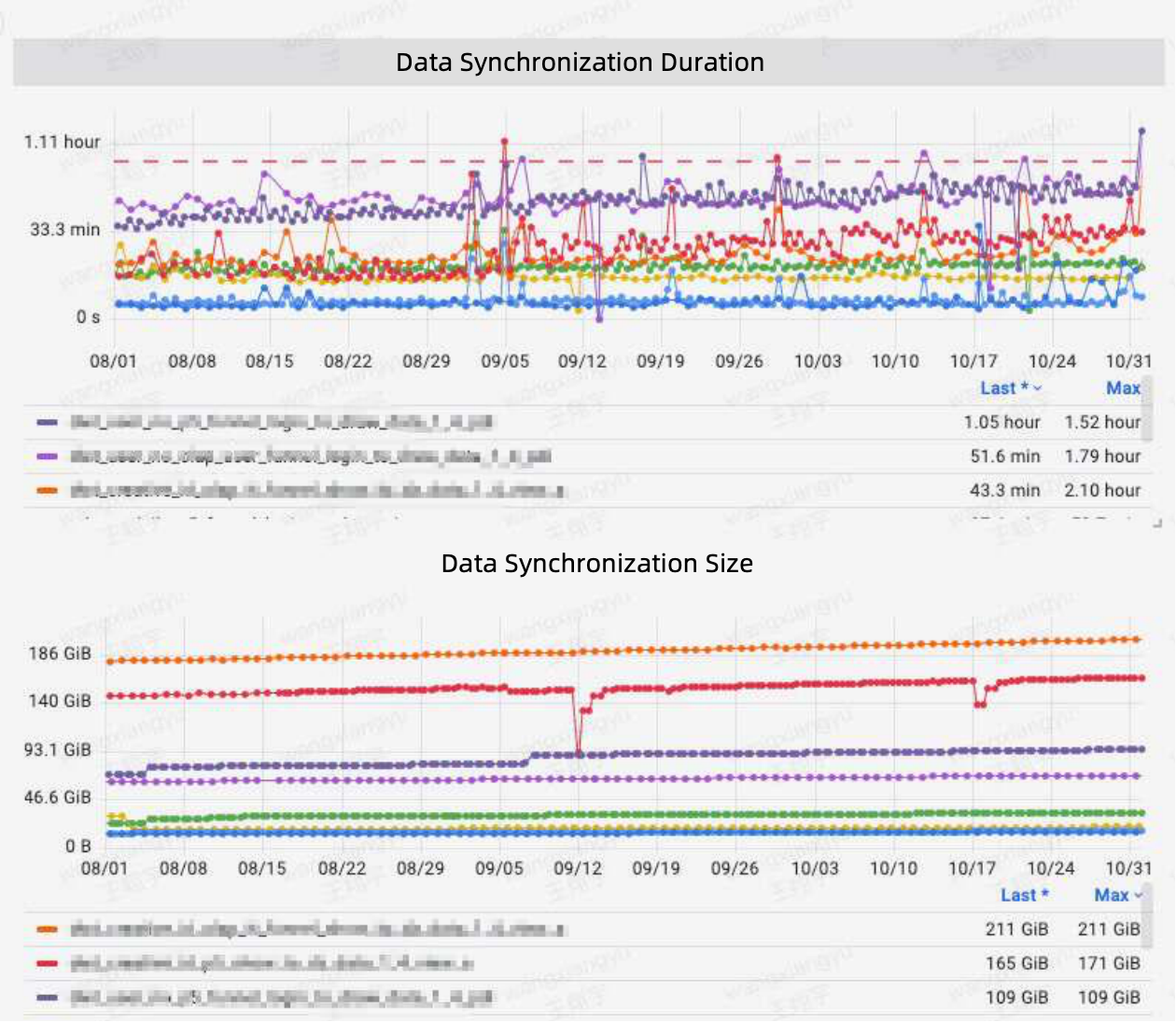
With Apache Doris, they ingest data via the Broker Load method and reach an SLA compliance rate of over 99% in terms of data synchronization performance.
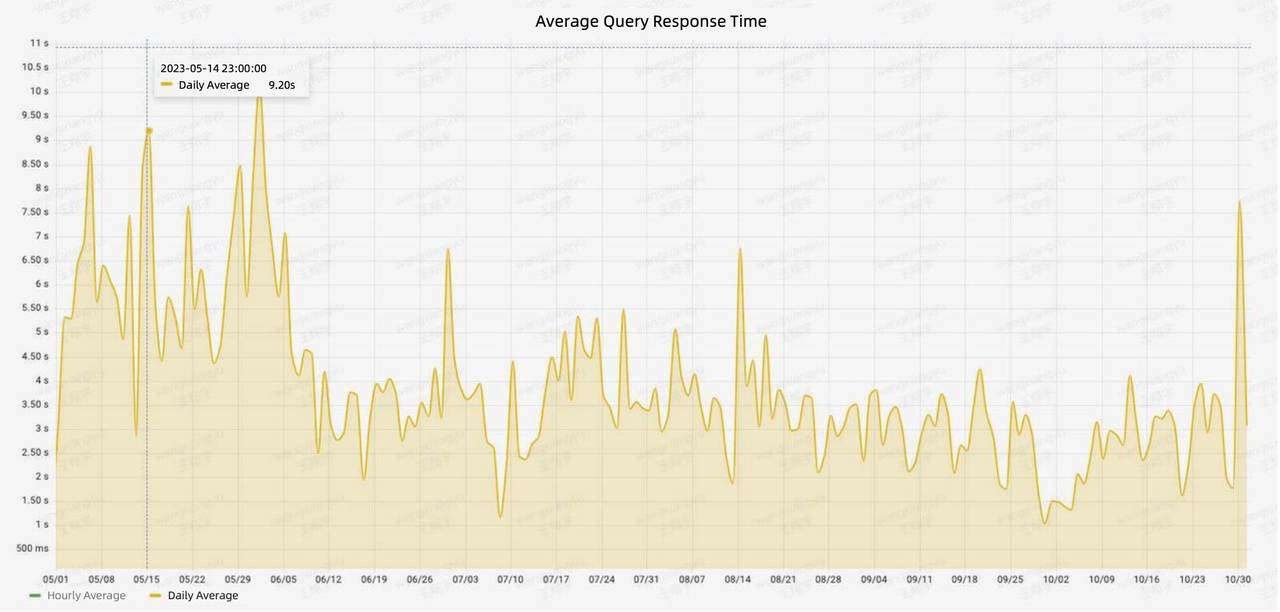
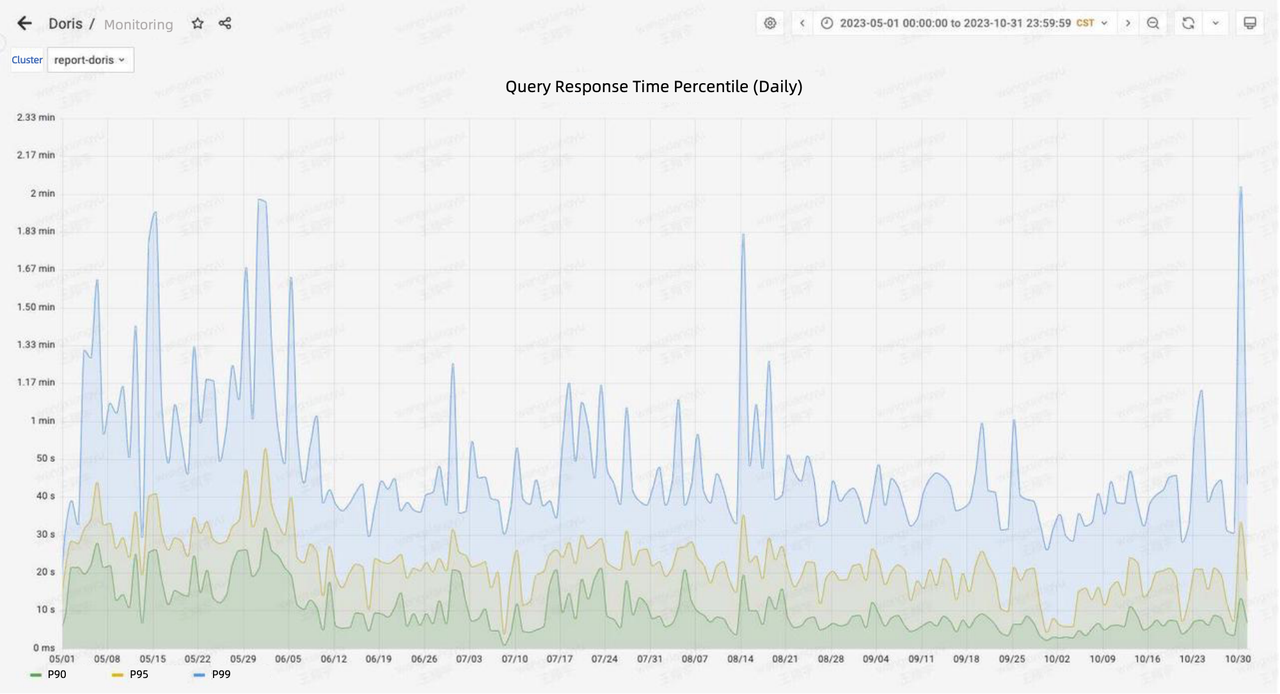
As for data queries, the Doris-based architecture maintains an average query response time of less than 10s and a P90 response time of less than 30s. This is a 50% speedup compared to the old architecture.
Tagging
Tagging is a common operation in customer analytics. You assign labels to customers based on their behaviors and characteristics, so that you can divide them into groups and figure out targeted marketing strategies for each group of them.
In the old processing architecture where Elasticsearch was the processing engine, raw data was ingested and tagged properly. Then, it will be merged into JSON files and imported into Elasticsearch, which provides data services for analysts and marketers. In this process, the merging step was to reduce updates and relieve load for Elasticsearch, but it turned out to be a troublemaker:
- Any problematic data in any of the tags could spoil the entire merging operation and thus interrupt the data services.
- The merging operation was implemented based on Spark and MapReduce and took up to 4 hours. Such a long time frame could encroach on marketing opportunities and lead to unseen losses.
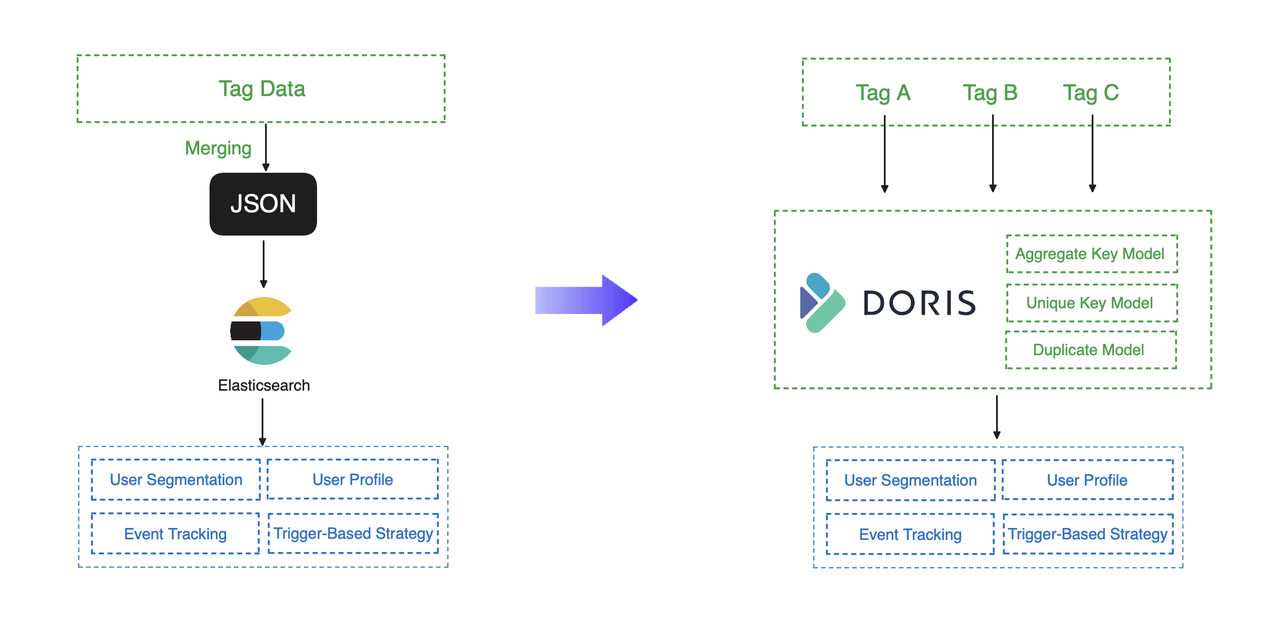
Then Apache Doris takes this over. Apache Doris arranges tag data with its data models, which process data fast and smoothly. The aforementioned merging step can be done by the Aggregate Key model, which aggregates tag data based on the specified Aggregate Key upon data ingestion. The Unique Key model is handy for partial column updates. Again, all you need is to specify the Unique Key. This enables swift and flexible data updating and saves you from the trouble of replacing the entire flat table. You can also put your detailed data into a Duplicate model to speed up certain queries. In practice, it took the user 1 hour to finish the data ingestion, compared to 4 hours with the old architecture.
In terms of query performance, Doris is equipped with well-developed bitmap indexes and techniques tailored to high-concurrency queries, so in this case, it can finish customer segmentation within seconds and reach over 700 QPS in user-facing queries.
Data lake analytics
In data lake scenarios, the data size you need to handle tends to be huge, but the data processing volume in each query tends to vary. To ensure fast data ingestion and high query performance of huge data sets, you need more resources. On the other hand, during non-peak time, you want to scale down your cluster for more efficient resource management. How do you handle this dilemma?
Apache Doris has a few features that are designed for data lake analytics, including Multi-Catalog and Compute Node. The former shields you from the headache of data ingestion in data lake analytics while the latter enables elastic cluster scaling.
The Multi-Catalog mechanism allows you to connect Doris to a variety of external data sources so you can use Doris as a unified query gateway without worrying about bulky data ingestion into Doris.
The Compute Node of Apache Doris is a backend role that is designed for remote federated query workloads, like those in data lake analytics. Normal Doris backend nodes are responsible for both SQL query execution and data management, while the Compute Nodes in Doris, as the name implies, only perform computation. Compute Nodes are stateless, making them elastic enough for cluster scaling.
The user introduces Compute Nodes into their cluster and deploys them with other components in a hybrid configuration. As a result, the cluster automatically scales down during the night, when there are fewer query requests, and scales out during the daytime to handle the massive query workload. This is more resource-efficient.
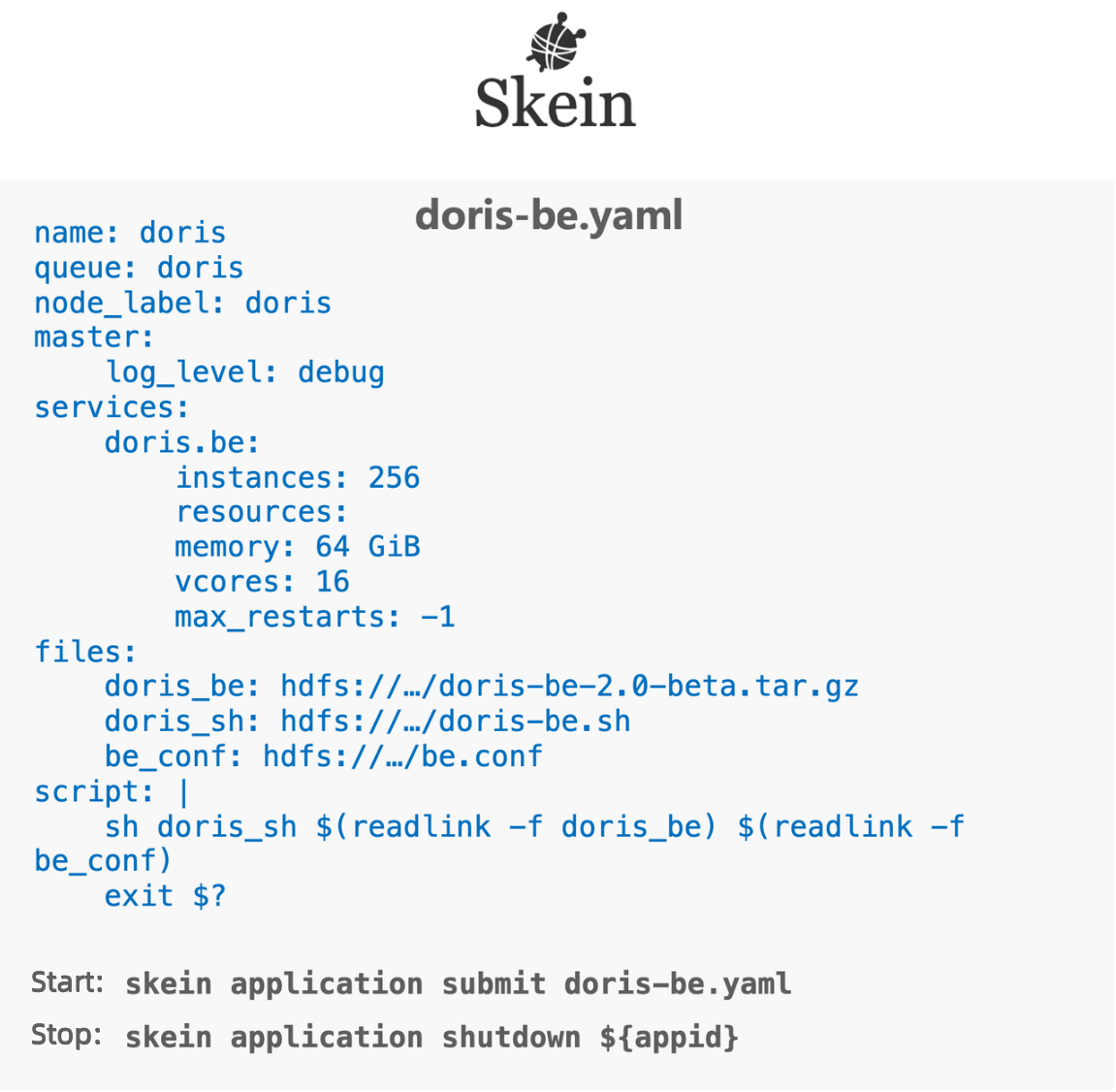
For easier deployment, they have also optimized their Deploy on Yarn process via Skein. As is shown below, they define the number of Compute nodes and the required resources in the YAML file, and then pack the installation file, configuration file, and startup script into the distributed file system. In this way, they can start or stop the entire cluster of over 100 nodes within minutes using one simple line of code.
Conclusion
For data reporting and customer tagging, Apache Doris smoothens data ingestion and merging steps, and delivers high query performance based on its own design and functionality. For data lake analytics, the user improves resource efficiency by elastic scaling of clusters using the Compute Node. Along their journey with Apache Doris, they have also developed a data ingestion task prioritizing mechanism and contributed it to the Doris project. A gesture to facilitate their use case ends up benefiting the whole open source community. This is a great example of open-source products thriving on user involvement.
Check Apache Doris repo on GitHub


